Clase 7 Feature Engineering y extensión del modelo lineal
Los modelos lineales (para regresión y clasificación) son modelos en principio simples que tienen la ventaja de que es relativamente fácil entender cómo contribuyen las variables de entrada a la predicción (simplemente describimos los coeficientes), es relativamente fácil ajustarlos, y es fácil hacer cálculos con ellos.
Sin embargo, puede ser que sean pobres desde el punto de vista predictivo. Hay dos razones:
Los coeficientes tienen varianza alta, de modo que las predicciones resultantes son inestables (por ejemplo, por pocos datos o variables de entradas correlacionadas). En este caso, vimos que con el enfoque de regularización ridge o lasso podemos mejorar la estabilidad, las predicciones, y obtener modelos más parsimoniosos.
El modelo tiene sesgo alto, en el sentido de que la estructura lineal es deficiente para describir patrones claros e importantes en los datos. Este problema puede suceder cuando tenemos relaciones complejas entre las variables. Cuando hay relativamente pocas entradas y suficientes datos, puede ser posible ajustar estructuras más realistas y complejas. Aunque veremos otros métodos para atacar este problema más adelante, a veces extensiones simples del modelo lineal pueden resolver este problema, que discutiremos en esta sección. Igualmente, esperamos encontrar mejores predicciones con modelos más realistas.
7.1 Feature engineering
El proceso de feature engineering es un proceso de creación, refinación y selección de entradas de los modelos. Este proceso es importante para obtener buenos resultados desde el punto de vista de desempeño predictivo.
Por ejemplo:
- ¿Cuándo conviene transformar variables para incluir en el modelo? Por ejemplo, transformaciones no lineales, categorización y técnicas asociadas.
- ¿Cuándo conviene producir nuevas variables con otras dadas como entradas al modelo? Por ejemplo, creación de interacciones o variables condicionales
- ¿Cómo resumir variables a distintas jerarquías? Por ejemplo, si la unidad de predicción es hogar, ¿cómo resumimos o incluimos los datos de nivel persona en el modelo?
- ¿Cómo tratar con valores atípicos o valores faltantes? Por ejemplo, creación de indicadores para datos faltantes, cuándo hacer imputación.
En todos estos casos, el primer punto importante es que debemos considerar este proceso de ingeniería como parte del ajuste, para evitar evaluaciones sesgadas:
- Las reglas de creación de variables deben estar definidas a nivel del conjunto de entrenamiento.
- El análisis exploratorio para descubrir transformaciones relevantes debe hacerse con el conjunto de entrenamiento también.
- Podemos usar validación cruzada o una muestra de validación para probar nuestro trabajo de feature engineering, y evitar sobreajuste.
7.2 Cómo hacer más flexible el modelo lineal
Veremos algunas técnicas de feature engineering para el modelo lineal:
La idea básica es entonces transformar a nuevas entradas, antes de ajustar un modelo: \[(x_1,...,x_p) \to (b_1(x),...,b_M (x)).\]
donde típicamente \(M\) es mayor que \(p\). Entonces, en lugar de ajustar el modelo lineal en las \(x_1,\ldots, x_p\), que es
\[ f(x) = \beta_0 + \sum_{i=1}^p \beta_jx_j\]
ajustamos un modelo lineal en las entradas transformadas:
\[ f(x) = \beta_0 + \sum_{i=1}^M \beta_jb_j(x).\]
Como cada \(b_j\) es una función que toma valores numéricos, podemos considerarla como una entrada derivada de las entradas originales.
Ejemplo
Si \(x_1\) es compras totales de un cliente de tarjeta de crédito, y \(x_2\) es el número de compras, podemos crear una entrada derivada \(b_1(x_1,x_2)=x_1/x_2\) que representa el tamaño promedio por compra. Podríamos entonces poner \(b_2(x_1,x_2)=x_1\), \(b_3(x_1,x_2)=x_2\), y ajustar un modelo lineal usando las entradas derivadas \(b_1,b_2, b_3\).
Lo conveniente de este enfoque es que lo único que hacemos para hacer más flexible el modelo es transformar en primer lugar las variables de entrada (quizá produciendo más entradas que el número de variables originales). Después construimos un modelo lineal, y todo lo que hemos visto aplica sin cambios: el modelo sigue siendo lineal, pero el espacio de entradas es diferente (generalmente expandido).
Veremos las siguientes técnicas:
- Agregar versiones transformadas de las variables de entrada.
- Incluir variables cualitativas (categóricas).
- Interacciones entre variables: incluir términos de la forma \(x_1x_2\).
- Regresión polinomial: incluír términos de la forma \(x_1^2\), \(x_1^3\), etcétera.
- Splines de regresión.
7.3 Transformación de entradas
Una técnica útil para mejorar el sesgo de modelos de regresión consiste en incluir o sustituir valores transformados de las variables numéricas de entrada.
Ejemplo: agregar entradas transformadas
Empezamos por predecir el valor de una casa en función de calidad de terminados.
Preparamos los datos:
install.packages("kableExtra")
library(kableExtra)
library(tidyverse)
library(tidymodels)
library(patchwork)
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7")
theme_set(theme_minimal())datos_casas <- read_csv("../datos/houseprices/house-prices.csv", na="") %>%
filter(SaleCondition == "Normal") %>%
mutate(precio_miles = SalePrice / 1000) %>%
select(-SalePrice) %>%
rename(piso_1_sf = `1stFlrSF`, piso_2_sf = `2ndFlrSF`)set.seed(9512)
casas_particion <- initial_split(datos_casas, 0.85)
casas_e <- training(casas_particion)Usaremos validación cruzada para ir checando nuestro trabajo. Ajustamos un modelo simple y lo probamos:
# preprocesamiento
receta_casas <- recipe(precio_miles ~ OverallQual, casas_e)
# modelo
mod_lineal <- linear_reg() %>% set_engine("lm")
# workflow
flow_1 <- workflow() %>%
add_recipe(receta_casas) %>%
add_model(mod_lineal)
ajuste_1 <- fit(flow_1, casas_e)graficar_evaluar <- function(flow_1, casas_e){
vc_particion <- vfold_cv(casas_e, v = 10)
ctrl <- control_resamples(save_pred = TRUE)
ajuste <- fit_resamples(flow_1, vc_particion,
metrics = metric_set(rsq, rmse),
control = ctrl)
metricas <- collect_metrics(ajuste) %>%
mutate(across(where(is.numeric), round, 2))
preds_vc <- collect_predictions(ajuste) %>% arrange(.row) %>%
bind_cols(casas_e %>% select(-precio_miles))
g_1 <- ggplot(preds_vc, aes(x = .pred, y = precio_miles)) +
geom_point() +
geom_abline() +
geom_smooth(se = FALSE, method = "loess") +
xlab("Predicción (val cruzada)") +
ylab("Precio de venta")
g_2 <- ggplot() + annotation_custom(gridExtra::tableGrob(metricas))
g_1 / g_2
}
graficar_evaluar(flow_1, casas_e)## `geom_smooth()` using formula 'y ~ x'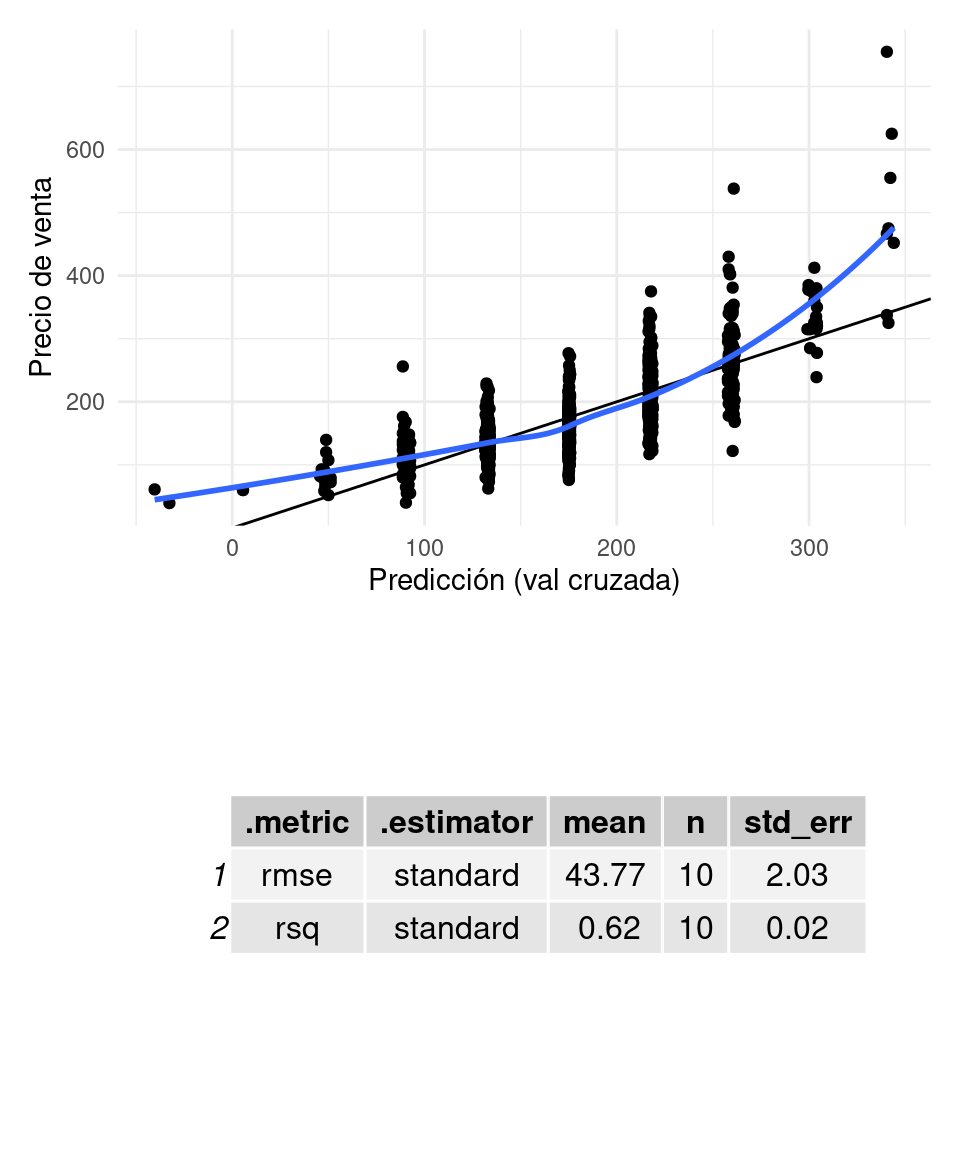
Y notamos que nuestras predicciones parecen estar sesgadas: tienden a ser bajas cuando el valor de la casa es alto o bajo. Esto es signo de sesgo, y usualmente implica que existen relaciones no lineales en las variables que estamos considerando, o interacciones que no estamos incluyendo en nuestro modelo.
Una técnica es agregar entradas derivadas de las que tenemos, usando transformaciones no lineales. Por ejemplo, podríamos hacer:
receta_casas <- receta_casas %>%
step_poly(OverallQual, degree = 2, options = list(raw = TRUE))
flow_2 <- workflow() %>% add_recipe(receta_casas) %>% add_model(mod_lineal)
ajuste_2 <- fit(flow_2, casas_e)
graficar_evaluar(flow_2, casas_e)## `geom_smooth()` using formula 'y ~ x'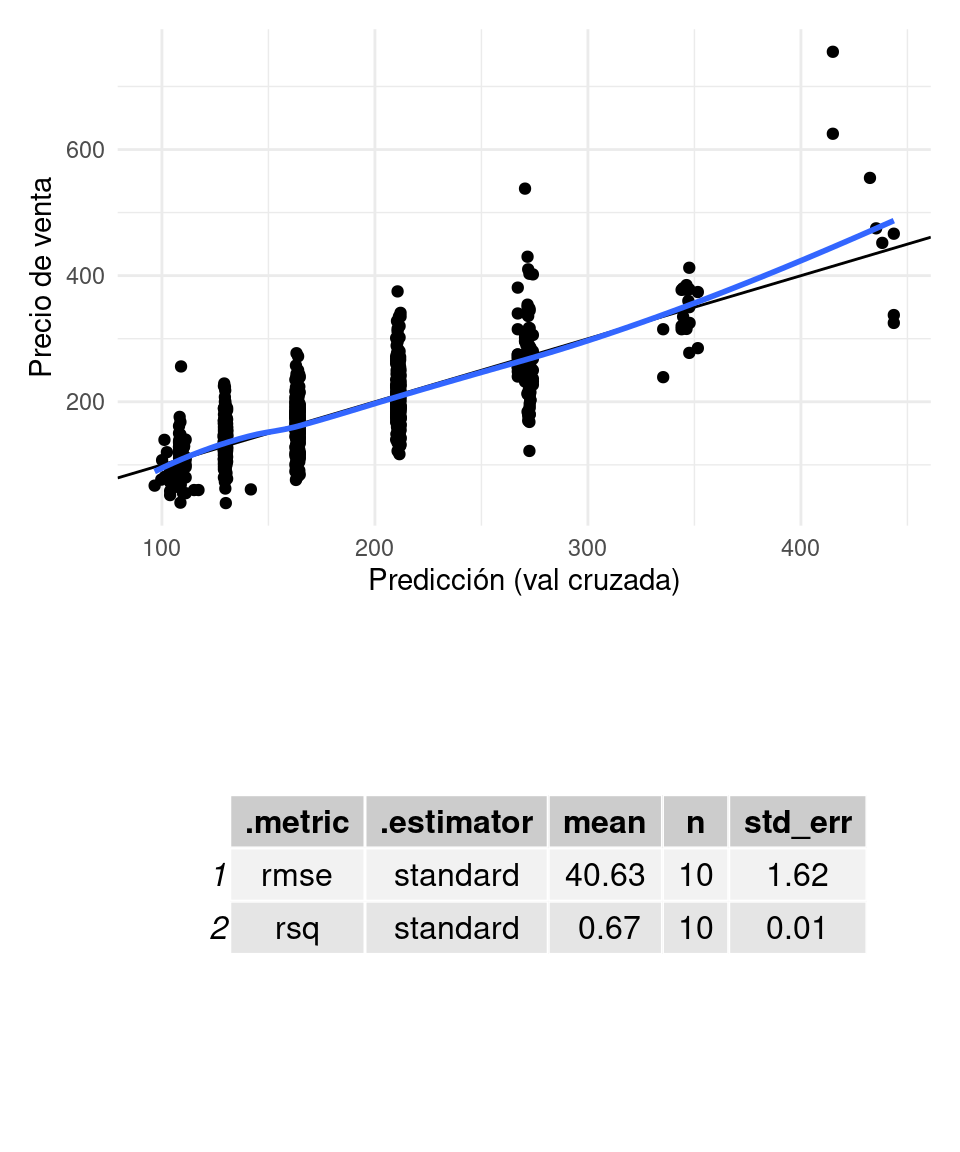
Y redujimos el error de validación. Esta reducción claramente proviene de una reducción de sesgo, pues usamos un modelo más complejo (una variable adicional).
Ahora agregamos otras variables importantes, que por conocimiento del dominio deberían estar incluídas de manera mínima: el tamaño del área habitable, garage y sótano, condición general, y quizá también la relación entre tamaño de piso 1 vs piso 2 (nótese que ponemos en el denominador el área del segundo piso):
receta_casas <- recipe(precio_miles ~ OverallQual + OverallCond +
GrLivArea + TotalBsmtSF + GarageArea +
piso_1_sf + piso_2_sf, casas_e) %>%
step_poly(OverallQual, degree = 2, options = list(raw = TRUE)) %>%
step_ratio(piso_2_sf, denom = denom_vars(piso_1_sf)) %>%
step_rm(piso_1_sf, piso_2_sf)
flow_2 <- workflow() %>% add_recipe(receta_casas) %>% add_model(mod_lineal)
ajuste_2 <- fit(flow_2, casas_e)
graficar_evaluar(flow_2, casas_e)## `geom_smooth()` using formula 'y ~ x'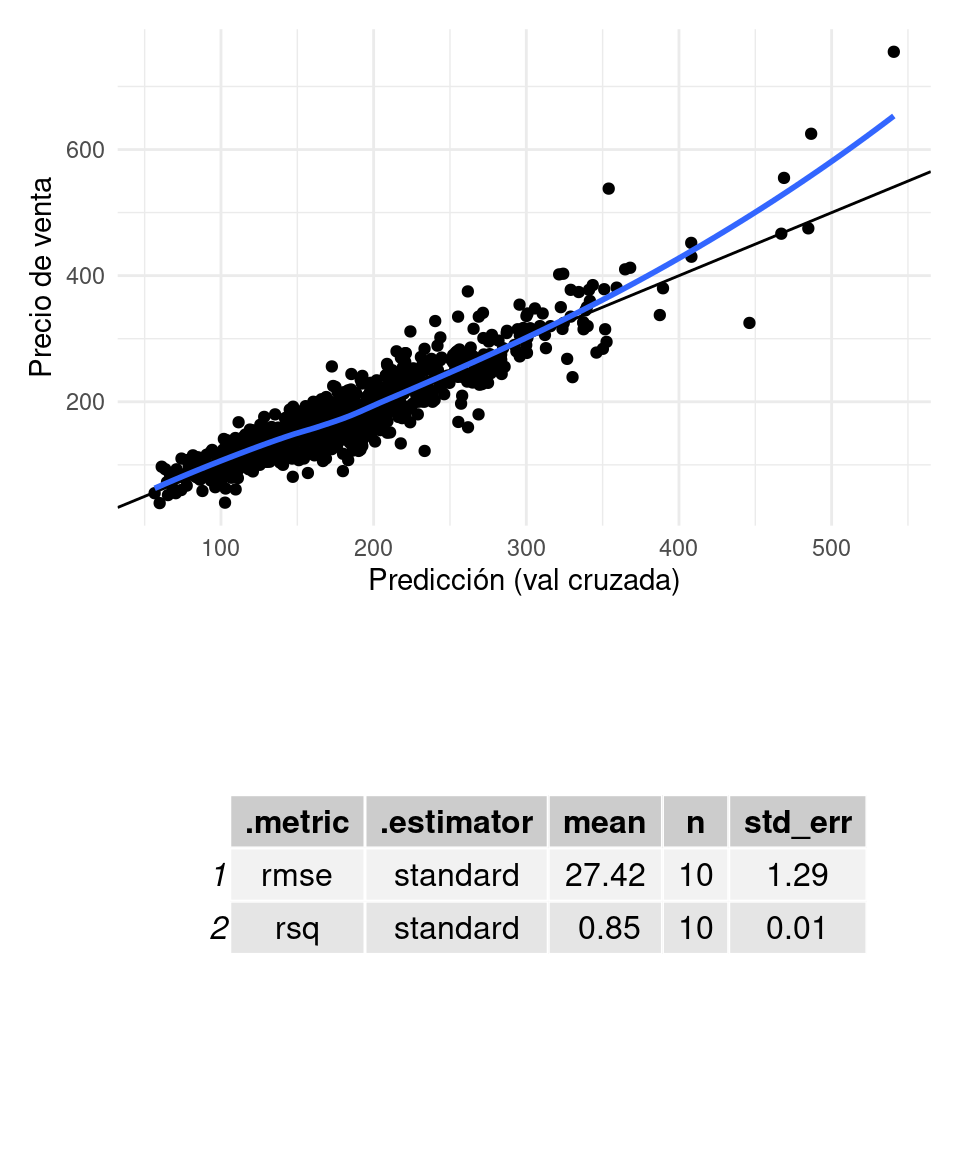
Observación: Podemos examinar la matriz de predictores que estamos usando viendo
juice(receta_casas %>% prep) %>% head() %>%
select(-precio_miles) %>%
knitr::kable(format = "html") %>%
scroll_box(width = "100%")| OverallCond | GrLivArea | TotalBsmtSF | GarageArea | OverallQual_poly_1 | OverallQual_poly_2 | piso_2_sf_o_piso_1_sf |
|---|---|---|---|---|---|---|
| 5 | 1710 | 856 | 548 | 7 | 49 | 0.9976636 |
| 5 | 1786 | 920 | 608 | 7 | 49 | 0.9413043 |
| 5 | 2198 | 1145 | 836 | 8 | 64 | 0.9196507 |
| 5 | 1362 | 796 | 480 | 5 | 25 | 0.7110553 |
| 6 | 2090 | 1107 | 484 | 7 | 49 | 0.8879855 |
| 6 | 1077 | 991 | 205 | 5 | 25 | 0.0000000 |
7.4 Variables cualitativas
Muchas veces queremos usar variables cualitativas como entradas de nuestro modelo. Pero en la expresión
\[ f(x) = \beta_0 + \sum_{i=1}^p \beta_jx_j,\] todas las entradas son numéricas. Podemos usar un truco simple para incluir variables cualitativas.
Ejemplo
Supongamos que queremos incluir la variable CentralAir, si tiene aire acondicionado central o no. Podemos ver en este análisis simple que, por ejemplo, controlando por tamaño de la casa, agrega valor tener aire acondicionado central:
## # A tibble: 2 x 2
## # Groups: CentralAir [2]
## CentralAir n
## <chr> <int>
## 1 N 63
## 2 Y 956ggplot(casas_e,
aes(x = GrLivArea, y = precio_miles, colour = CentralAir, group = CentralAir)) +
geom_jitter(alpha = 1) +
geom_smooth(method = 'lm', se=FALSE, size=1.5) ## `geom_smooth()` using formula 'y ~ x'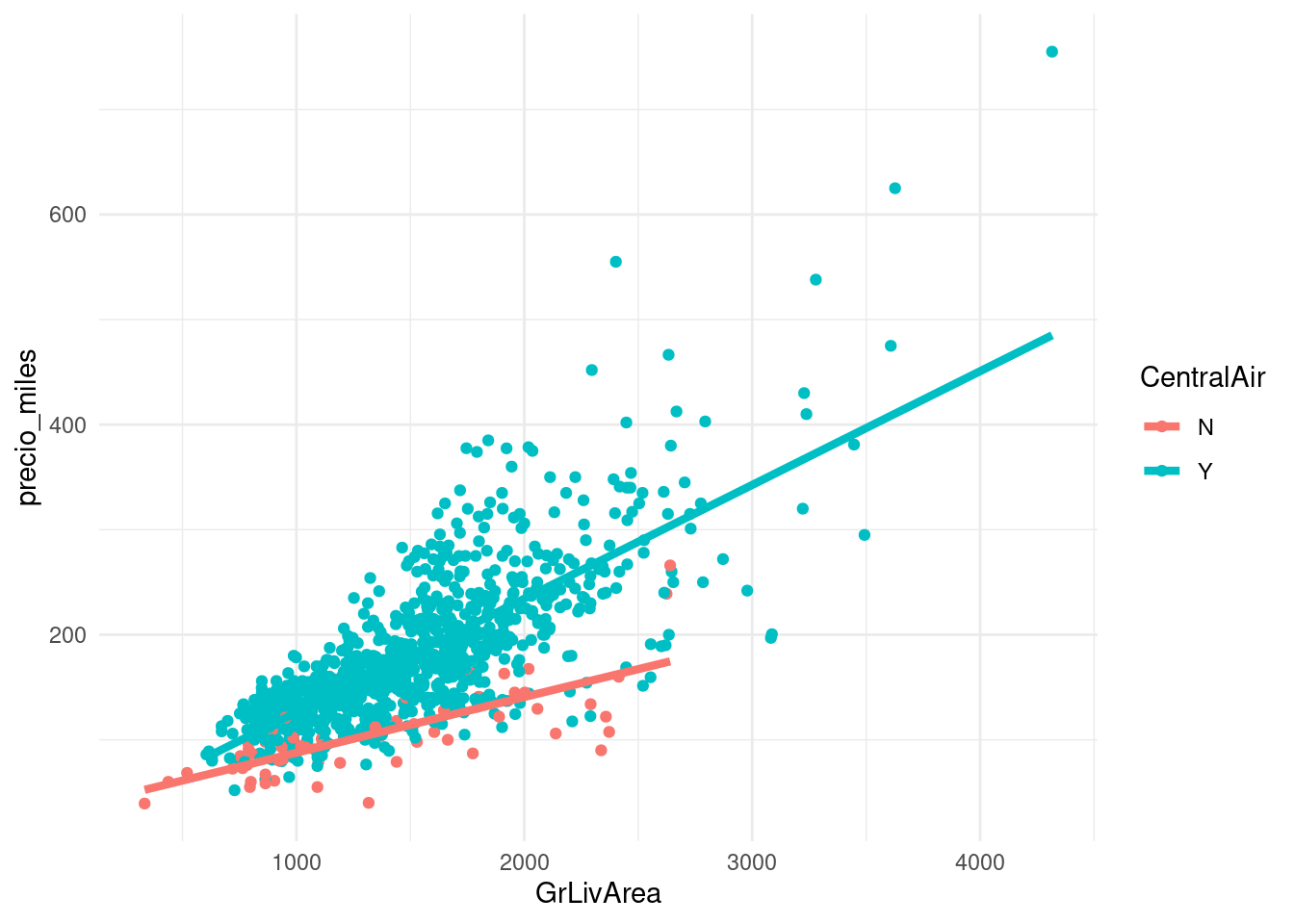
Podemos incluir de manera simple esta variable creando una variable dummy o indicadora, que toma el 1 cuando la casa tiene AC y 0 si no. Nótese también que las pendientes parecen diferentes. Esto lo discutiremos más adelante.
Y ahora podemos hacer:
receta_casas <- recipe(precio_miles ~ OverallQual + OverallCond +
GrLivArea + TotalBsmtSF + GarageArea +
piso_1_sf + piso_2_sf + CentralAir, casas_e) %>%
step_poly(OverallQual, degree = 2, options = list(raw = TRUE)) %>%
step_ratio(piso_2_sf, denom = denom_vars(piso_1_sf)) %>%
step_rm(piso_1_sf, piso_2_sf) %>%
step_dummy(CentralAir)
flow_2 <- workflow() %>% add_recipe(receta_casas) %>% add_model(mod_lineal)
ajuste_2 <- fit(flow_2, casas_e)
graficar_evaluar(flow_2, casas_e)## `geom_smooth()` using formula 'y ~ x'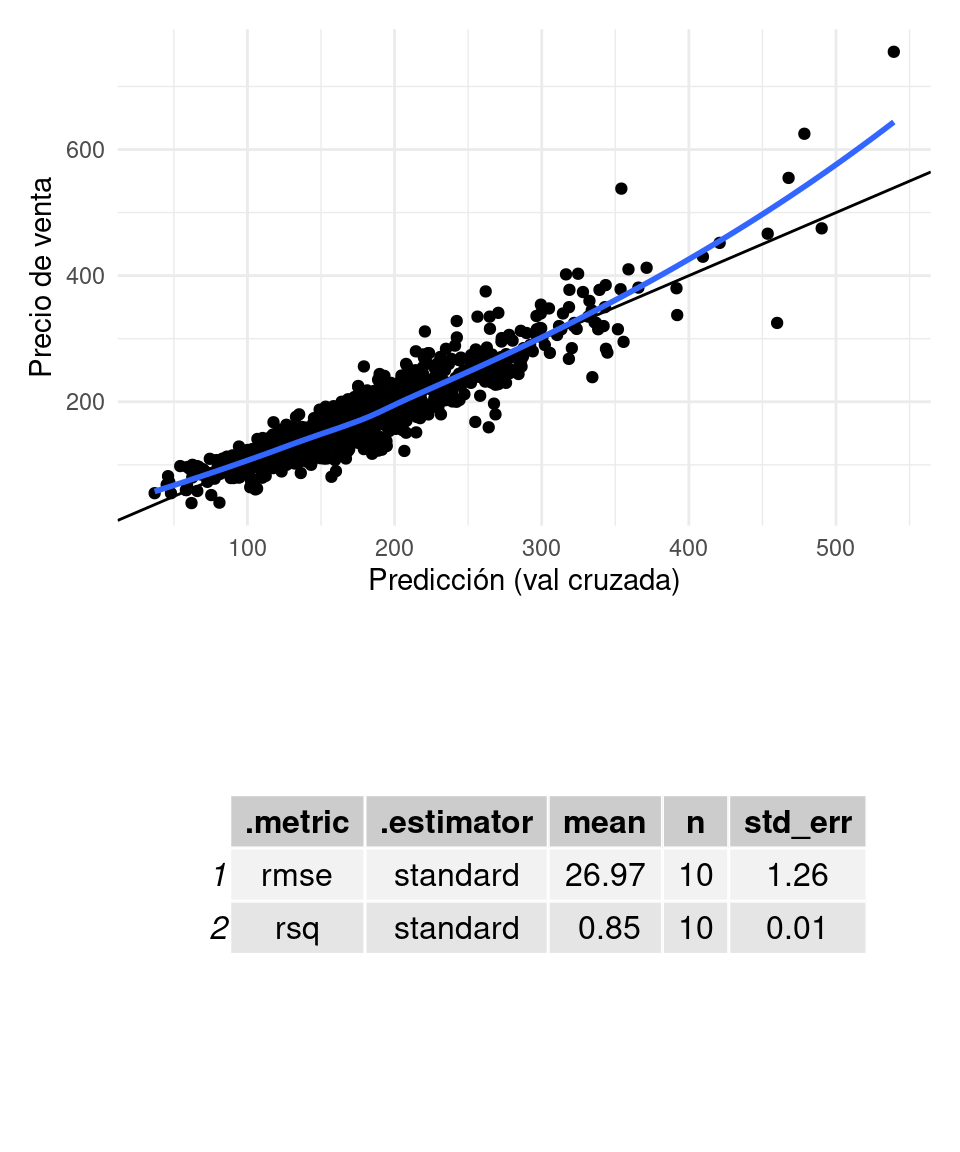
Que no es una gran mejora, pero esperado dado que pocas de estas casas tienen aire acondicionado. La matriz de entradas se ve como sigue:
juice(receta_casas %>% prep) %>% head() %>% knitr::kable(format = "html") %>%
scroll_box(width = "100%")| OverallCond | GrLivArea | TotalBsmtSF | GarageArea | precio_miles | OverallQual_poly_1 | OverallQual_poly_2 | piso_2_sf_o_piso_1_sf | CentralAir_Y |
|---|---|---|---|---|---|---|---|---|
| 5 | 1710 | 856 | 548 | 208.5 | 7 | 49 | 0.9976636 | 1 |
| 5 | 1786 | 920 | 608 | 223.5 | 7 | 49 | 0.9413043 | 1 |
| 5 | 2198 | 1145 | 836 | 250.0 | 8 | 64 | 0.9196507 | 1 |
| 5 | 1362 | 796 | 480 | 143.0 | 5 | 25 | 0.7110553 | 1 |
| 6 | 2090 | 1107 | 484 | 200.0 | 7 | 49 | 0.8879855 | 1 |
| 6 | 1077 | 991 | 205 | 118.0 | 5 | 25 | 0.0000000 | 1 |
Cuando la variable categórica tiene \(K\) clases, solo creamos variables indicadores de las primeras \(K-1\) clases, pues la dummy de la última clase tiene información redundante: es decir, si para las primeras \(K-1\) clases las variables dummy son cero, entonces ya sabemos que se trata de la última clase \(K\), y no necesitamos incluir una indicadora para la última clase.
Ejemplo
Vamos a incluir la variable BsmtQual, que tiene los niveles:
## # A tibble: 5 x 2
## # Groups: BsmtQual [5]
## BsmtQual n
## <chr> <int>
## 1 Ex 57
## 2 Fa 24
## 3 Gd 433
## 4 NA 22
## 5 TA 483Nótese que codificamos como NA, que vemos como una categoría más (le puedes poner “no disponible”, por ejemplo), cuando este dato no está disponible. En este caso, la razón de que no está disponible es que está asociada con casas que no tienen sótano.
Podemos hacer una gráfica exploratoria como la anterior:
ggplot(casas_e,
aes(x=GrLivArea, y=precio_miles, colour=BsmtQual, group=BsmtQual)) +
geom_jitter(alpha=1) +
geom_smooth(method='lm', se=FALSE, size=1.5) ## `geom_smooth()` using formula 'y ~ x'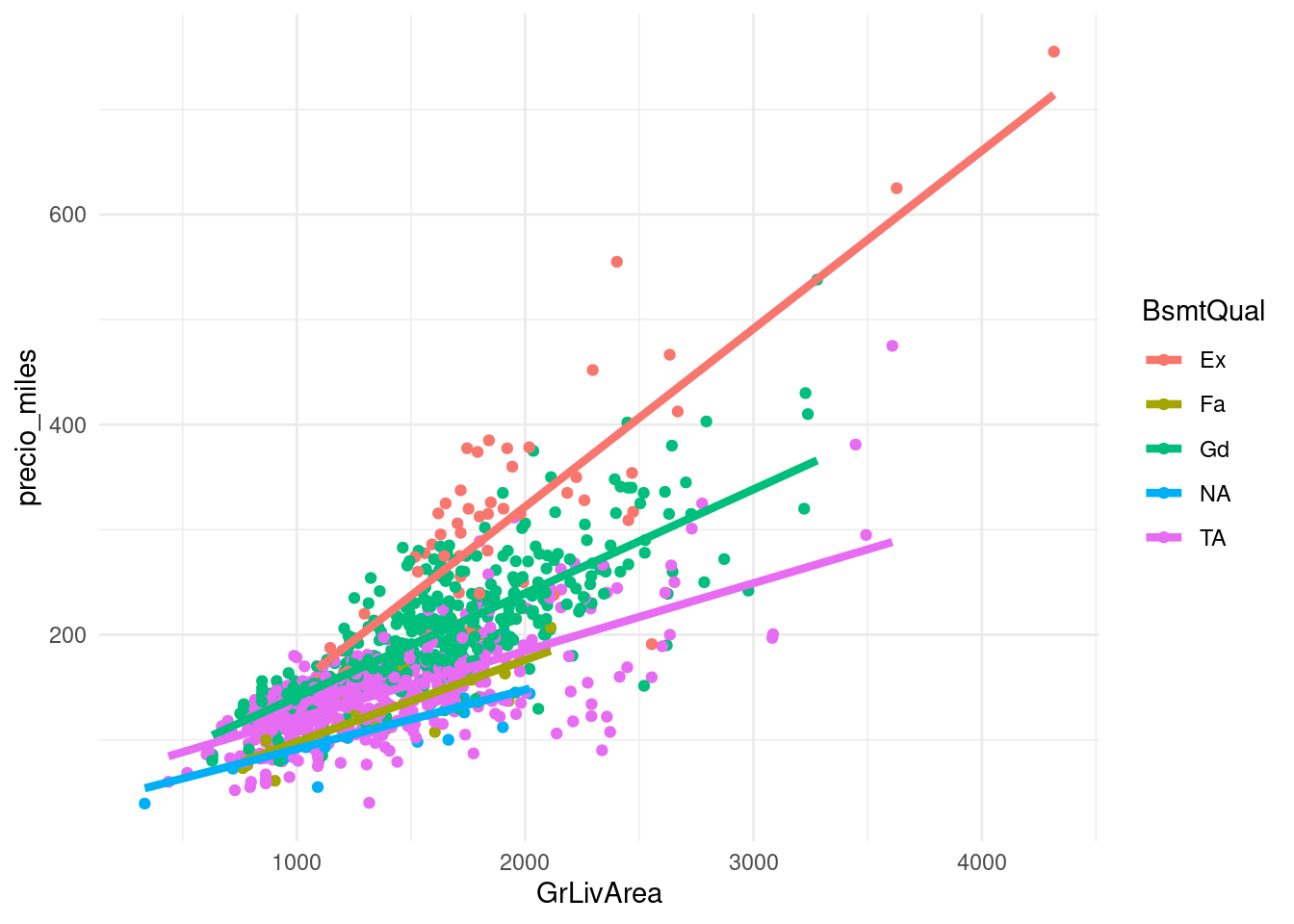
donde vemos que esta variable puede aportar a la predicción. Ajustamos y evaluamos:
receta_casas <- recipe(precio_miles ~ OverallQual + OverallCond +
GrLivArea + TotalBsmtSF + GarageArea +
piso_1_sf + piso_2_sf + CentralAir + BsmtQual,
casas_e) %>%
step_poly(OverallQual, degree = 2, options = list(raw = TRUE)) %>%
step_ratio(piso_2_sf, denom = denom_vars(piso_1_sf)) %>%
step_rm(piso_1_sf, piso_2_sf) %>%
step_relevel(BsmtQual, ref_level = "NA") %>%
step_dummy(CentralAir, BsmtQual)
flow_2 <- workflow() %>% add_recipe(receta_casas) %>% add_model(mod_lineal)
ajuste_2 <- fit(flow_2, casas_e)
graficar_evaluar(flow_2, casas_e)## `geom_smooth()` using formula 'y ~ x'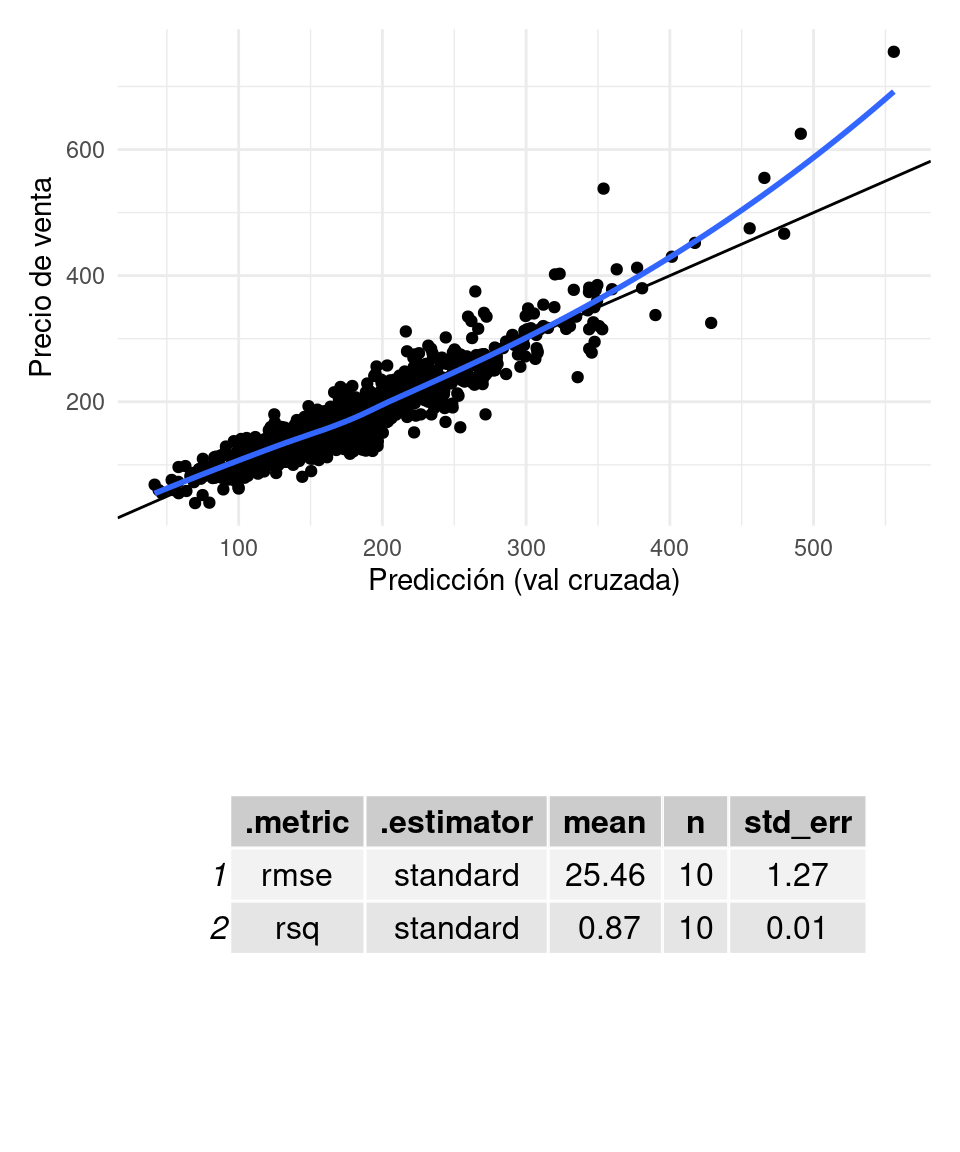
Si examinamos los coeficientes, vemos que no aparece el coeficiente de NA, que corresponde a casas que no tienen sótano. Este es el nivel de referencia y podemos pensar que su coeficiente es 0.
ajuste_2 %>% pull_workflow_fit() %>% tidy %>%
select(term, estimate, std.error) %>%
mutate(across(!starts_with("term"), round, 2)) %>%
DT::datatable()Nótese que los coeficientes de esta variable no se pueden interpretar sin considerar TotalBsmntSF, que vale cero cuando la casa no tienen sótano. Por ejemplo, observamos que los niveles Fair y TA (typical) están por debajo del nivel de referencia (sin sótano). La interpretación de este hecho no es tan simple por dos razones:
- Estos niveles negativos aparecen con contribución positivas del área del sótano. Cuando la variable de Calidad es NA, entonces TotalBsmtSF es cero. Podria ayudar en la interpretación centrar esta variable.
- El modelo todavía no está bien especificado: es de esperar que haya una interacción entre área del sótano y su calidad. Discutiremos esto más adelante
- Puede ser también que estemos sufriendo de sobreajuste y coeficientes ruidosos, pues algunos niveles tienen pocos datos.
7.5 Interacciones
En el modelo lineal, cada variable contribuye de la misma manera independientemente de los valores de las otras variables. Esta es un simplificación o aproximación útil, pero muchas veces puede producir sesgo demasiado grande en el modelo. Por ejemplo: consideremos los siguientes datos de la relación de mediciones de temperatura y ozono en la atmósfera:
Ejemplo
## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6air <- filter(airquality, !is.na(Ozone) & !is.na(Wind) & !is.na(Temp))
lm(Ozone ~Temp, data = air[1:80,])##
## Call:
## lm(formula = Ozone ~ Temp, data = air[1:80, ])
##
## Coefficients:
## (Intercept) Temp
## -136.474 2.306set.seed(9132)
air <- sample_n(air, 116)
ggplot(air[1:50,], aes(x = Temp, y = Ozone)) + geom_point() +
geom_smooth(method = 'lm', se = FALSE)## `geom_smooth()` using formula 'y ~ x'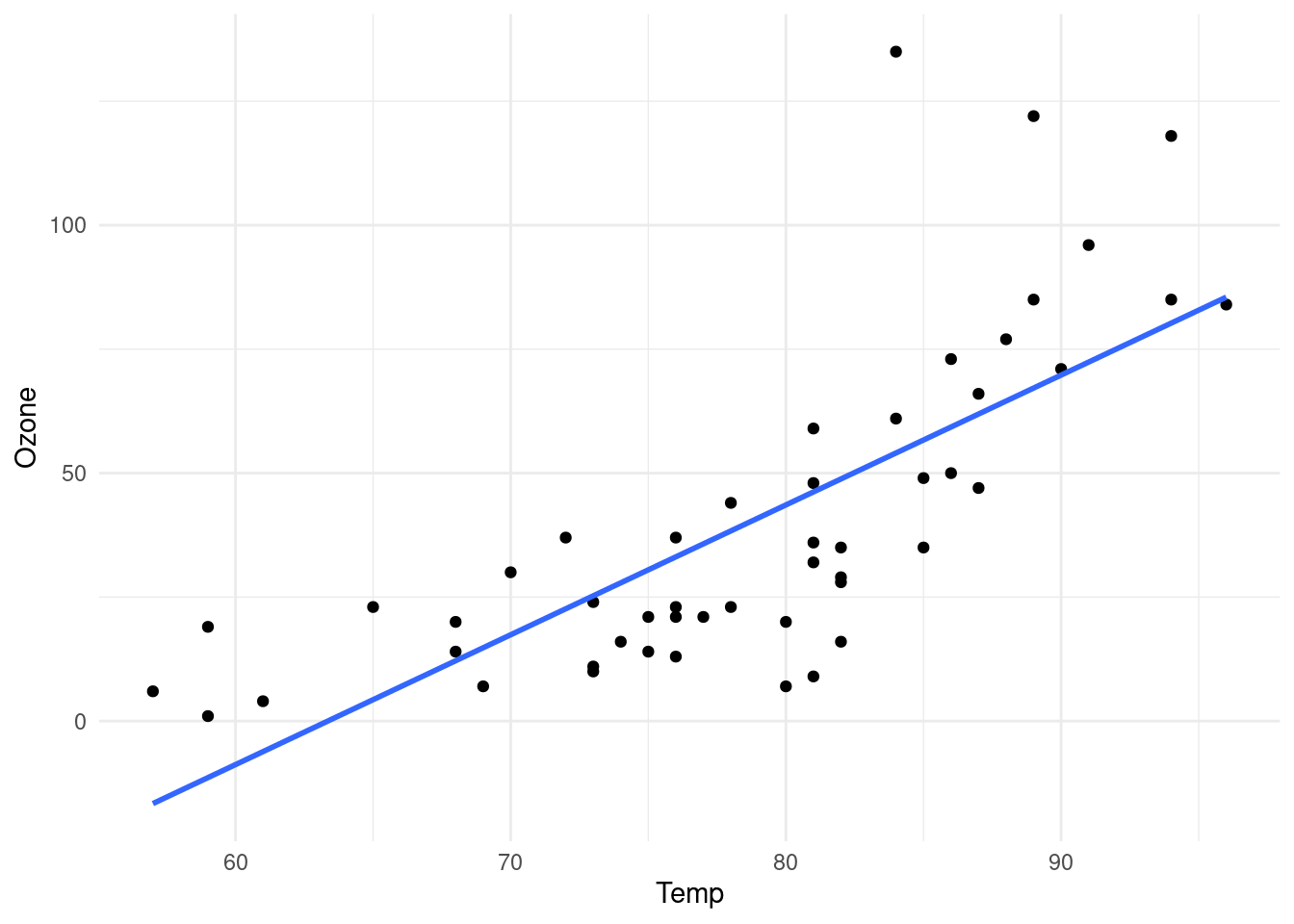
Y notamos un sesgo posible en nuestro modelo. Si coloreamos por velocidad del viento:
cuantiles <- quantile(air$Wind)
ggplot(air[1:50,], aes(x = Temp, y = Ozone, colour= cut(Wind, cuantiles))) +
geom_point() + geom_smooth(method = 'lm', se = FALSE)## `geom_smooth()` using formula 'y ~ x'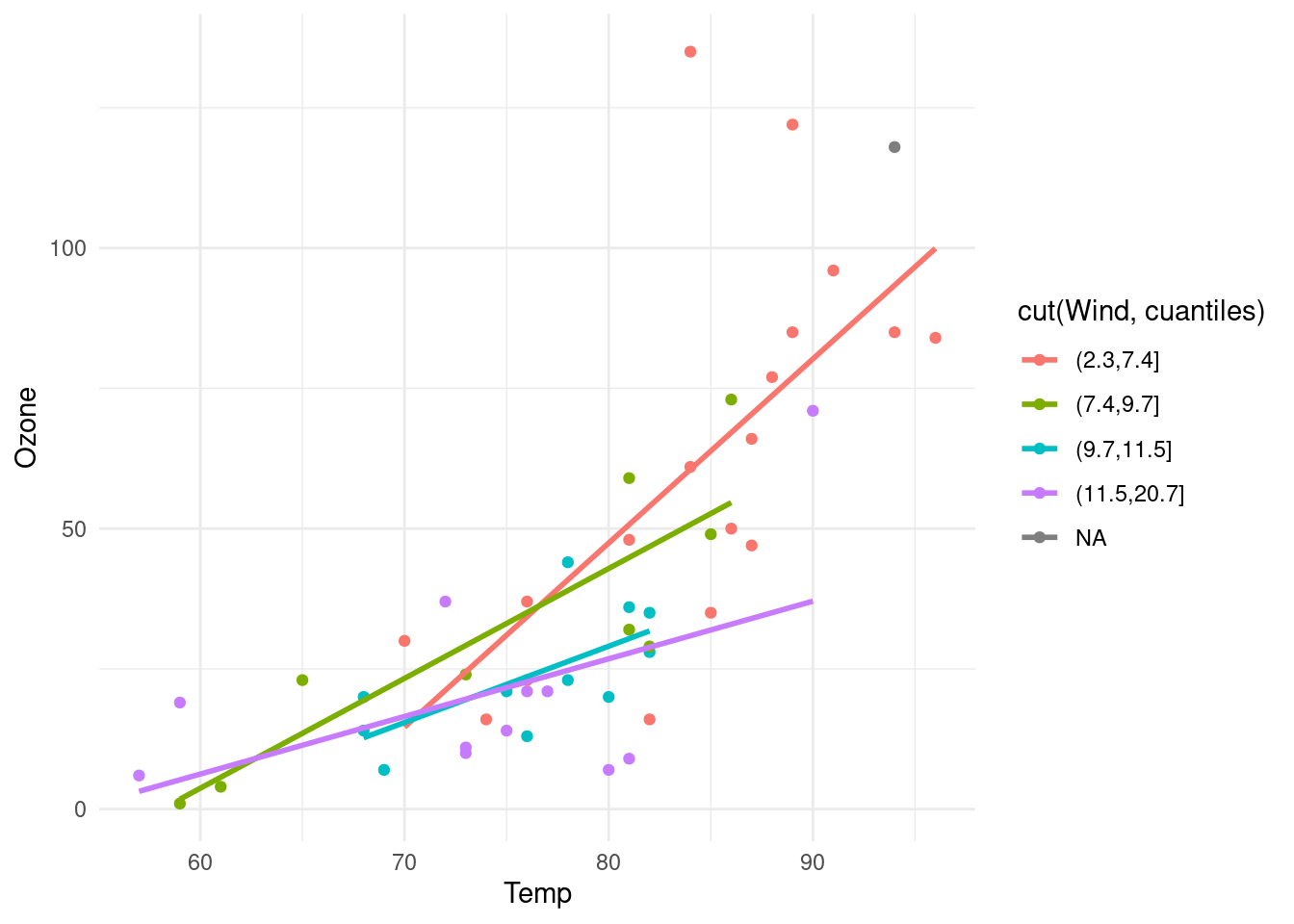
Nótese que parece ser que cuando los niveles de viento son altos, entonces hay una relación más fuerte entre temperatura y Ozono. Esto es una interacción de temperatura y viento.
Podemos hacer los siguiente: incluír un factor adicional, el producto de temperatura con viento:
air$temp_wind <- air$Temp*air$Wind
mod_a0 <- lm(Ozone ~ Temp, data = air[1:50,])
mod_a1 <- lm(Ozone ~ Temp + Wind, data = air[1:50,])
mod_a2 <- lm(Ozone ~ Temp + Wind + temp_wind, air[1:50,])
mod_a2##
## Call:
## lm(formula = Ozone ~ Temp + Wind + temp_wind, data = air[1:50,
## ])
##
## Coefficients:
## (Intercept) Temp Wind temp_wind
## -311.3641 4.7943 19.6447 -0.2899pred_0 <- predict(mod_a0, newdata = air[51:116,])
pred_1 <- predict(mod_a1, newdata = air[51:116,])
pred_2 <- predict(mod_a2, newdata = air[51:116,])
mean(abs(pred_0-air[51:116,'Ozone']))## [1] 18.55177## [1] 16.71354## [1] 16.17652Podemos interpretar el modelo con interacción de la siguiente forma:
- Si \(Wind = 5\), entonces la relación Temperatura <-> Ozono es: \[ Ozono = -290 + 4.5Temp + 14.6(5) - 0.2(Temp)(5) = -217 + 3.5Temp\]
- Si \(Wind=10\), entonces la relación Temperatura <-> Ozono es: \[ Ozono = -290 + 4.5Temp + 14.6(15) - 0.2(Temp)(15) = -71 + 1.5Temp\]
Incluir interacciones en modelos lineales es buena idea para problemas con un número relativamente chico de variables (por ejemplo, \(p < 10\)). En estos casos, conviene comenzar agregando interacciones entre variables que tengan efectos relativamente grandes en la predicción. No es tan buena estrategia para un número grande de variables: por ejemplo, para clasificación de dígitos, hay 256 entradas. Poner todas las interacciones añadiría más de 30 mil variables adicionales, y es difícil escoger algunas para incluir en el modelo a priori.
Pueden escribirse interacciones en fórmulas de lm y los cálculos se hacen automáticamente:
##
## Call:
## lm(formula = Ozone ~ Temp + Wind + Temp:Wind, data = air[1:50,
## ])
##
## Coefficients:
## (Intercept) Temp Wind Temp:Wind
## -311.3641 4.7943 19.6447 -0.2899Ejemplo
En nuestro ejemplo de precios de casas ya habíamos intentado utilizar una interacción, considerando el cociente de dos variables. Aquí veremos otras que por conocimiento experto y por análisis que hicimos arriba, deberíamos de considerar también. Por las que vimos arriba:
- Interacción de calidad de Sótano con Tamaño de Sótano, y otras similares
- Interacción de Aire acondicionado con tamaño
- Interacción de calidad general con tamaño, por ejemplo:
Observamos que en nuestro modelo la calidad y condición sólo puede aumentar una cantidad fija al precio de venta. En realidad, dependiendo de la calidad y condición, deberíamos obtener distintos precios por metro cuadrado. Por ejemplo, si graficamos
casas_e <- casas_e %>% mutate(grupo_calidad = cut(OverallQual, c(0, 4, 6, 8, 10)))
ggplot(casas_e, aes(x = GrLivArea, y = precio_miles, colour = grupo_calidad,
group = grupo_calidad)) +
geom_point(alpha = 0.3) +
geom_smooth(method = "loess", se = FALSE, span = 1, method.args = list(degree = 1)) +
scale_colour_manual(values = cbbPalette)## `geom_smooth()` using formula 'y ~ x'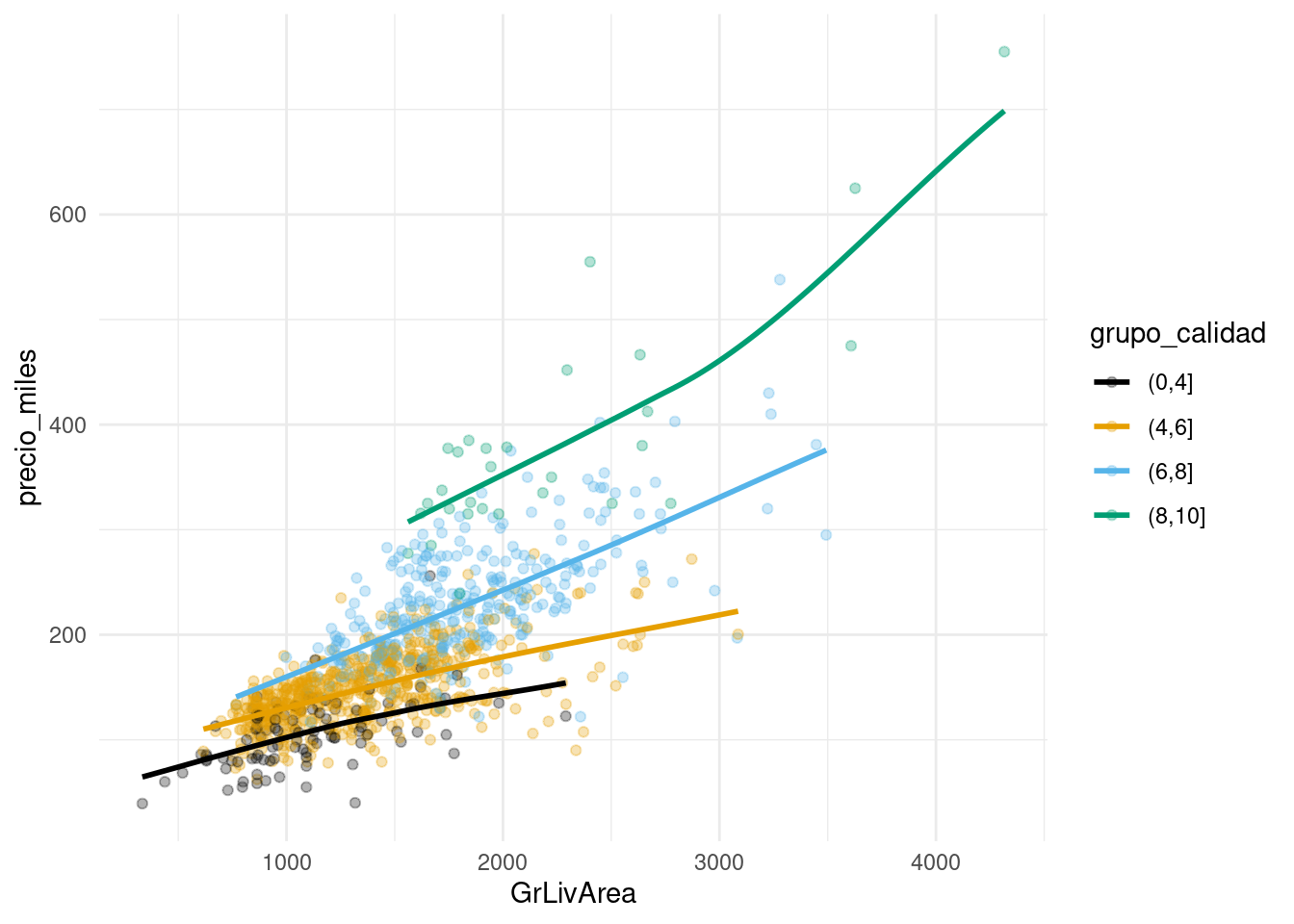
vemos que las pendientes son distintas. Esto sugiere agregar la interacción de Calidad con Área. Probemos nuestro en nuestro modelo. Aunque podemos agregar todas las interacciones posibles, en este caso sólo tomamos aquellas que tienen un número relativamente grande de observaciones:
receta_casas <- recipe(precio_miles ~ OverallQual + OverallCond +
GrLivArea + TotalBsmtSF + GarageArea +
piso_1_sf + piso_2_sf + CentralAir + BsmtQual,
casas_e) %>%
step_interact(~ OverallQual:GrLivArea) %>%
step_poly(OverallQual, degree = 2) %>%
step_ratio(piso_2_sf, denom = denom_vars(piso_1_sf)) %>%
step_rm(piso_1_sf, piso_2_sf) %>%
step_relevel(BsmtQual, ref_level = "TA") %>%
step_dummy(CentralAir, BsmtQual) %>%
step_interact(~ matches("BsmtQual_Ex", "BSmtQual_Gd"):TotalBsmtSF)
# ajustar flujo
flow_2 <- workflow() %>% add_recipe(receta_casas) %>% add_model(mod_lineal)
ajuste_2 <- fit(flow_2, casas_e)
graficar_evaluar(flow_2, casas_e)## `geom_smooth()` using formula 'y ~ x'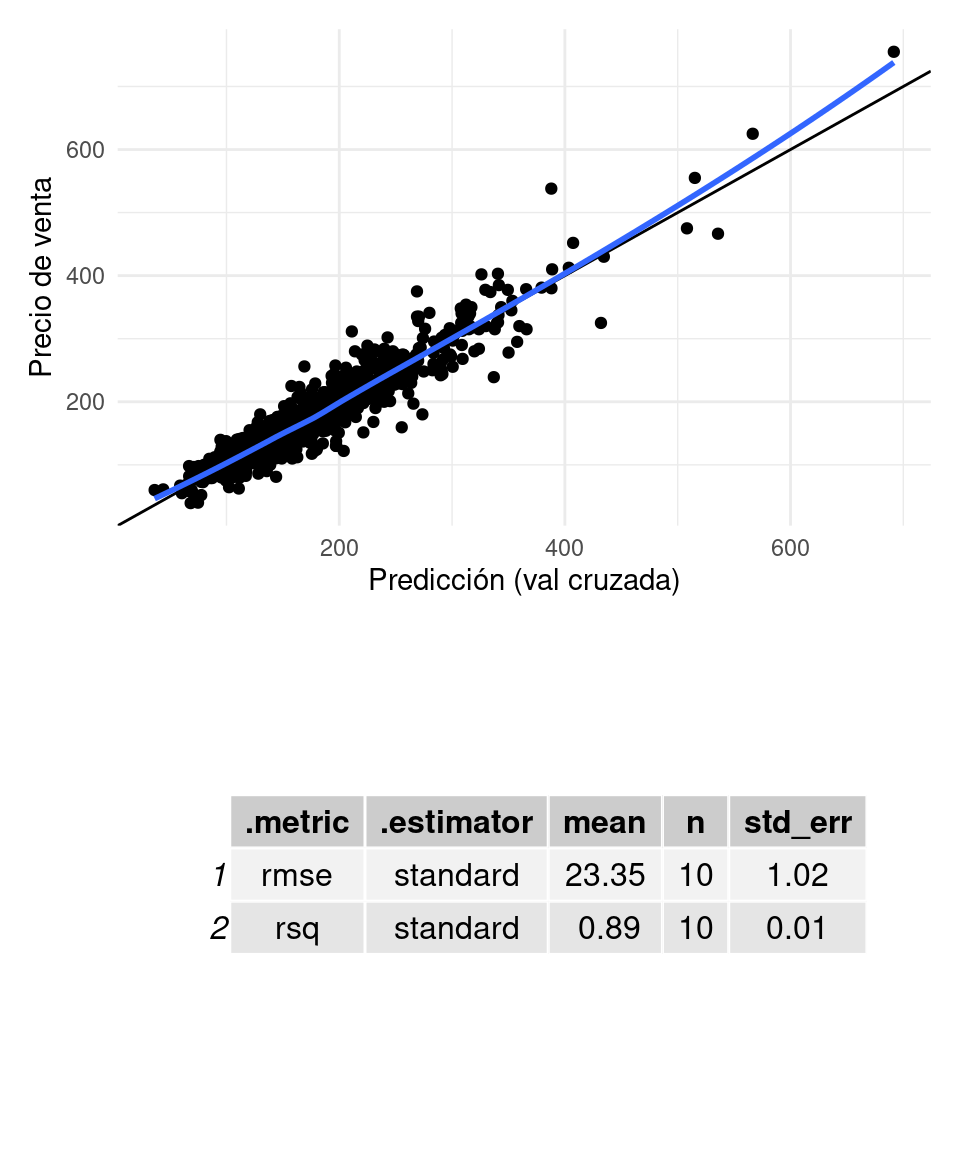 que muestra una mejoría con respecto a modelos anteriores.
que muestra una mejoría con respecto a modelos anteriores.
Podemos considerar otra adicional: no hemos considerado el vecindario, ni que la relación entre precio y superficie puede tener interacción con el vecindario, pues distintos vecindarios tienen distintos precios por metro cuadrado:
casas_e %>% group_by(Neighborhood) %>%
summarise(media_ft2 = mean(precio_miles / GrLivArea), n = n()) %>%
arrange(desc(media_ft2)) ## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 25 x 3
## Neighborhood media_ft2 n
## <chr> <dbl> <int>
## 1 NridgHt 0.157 40
## 2 StoneBr 0.153 16
## 3 Veenker 0.149 7
## 4 Timber 0.142 24
## 5 CollgCr 0.137 105
## 6 NoRidge 0.135 31
## 7 Somerst 0.135 41
## 8 Blmngtn 0.133 11
## 9 Mitchel 0.131 39
## 10 ClearCr 0.128 21
## # … with 15 more rowsVecindario es una variable nominal, y podemos ver que tendremos algunas dificultades pues hay vecindarios que tienen muy pocas observaciones:
- La estimación de coeficientes para estos vecindarios con pocas observaciones será ruidosa o poco precisa. Aunque el sesgo mejore, la varianza de las predicciones puede empeorar.
- Dado que algunas zonas tienen apenas unas cuantas observaciones, no sería sorprendente encontrar al momento de predecir en el futuro nuevos vecindarios que no habíamos observado antes. Tenemos que prepararnos para esto.
Una manera de tratar este problema es agrupar las categorías chicas en una categoría de “Otros”. Si encontramos algunos casos de nuevas categorías en los datos podemos ponerlas en esta categoría.
modelo_reg <- linear_reg(penalty = 0.01, mixture = 0.1) %>% set_engine("glmnet")
receta_casas <- recipe(precio_miles ~ Neighborhood + OverallQual + OverallCond +
GrLivArea + TotalBsmtSF + GarageArea + CentralAir +
piso_1_sf + piso_2_sf + BsmtQual, casas_e) %>%
step_interact(~ OverallQual:GrLivArea) %>%
step_poly(OverallQual, degree = 2) %>%
step_ratio(piso_2_sf, denom = denom_vars(piso_1_sf)) %>%
step_rm(piso_1_sf, piso_2_sf) %>%
step_relevel(BsmtQual, ref_level = "TA") %>%
step_dummy(CentralAir, BsmtQual, one_hot = TRUE) %>%
step_interact(~ matches("BsmtQual_Ex", "BsmtQual_Gd"):TotalBsmtSF) %>%
step_other(Neighborhood, threshold = 50) %>%
step_dummy(Neighborhood, one_hot = TRUE)
# ajustar flujo
flow_2 <- workflow() %>% add_recipe(receta_casas) %>% add_model(modelo_reg)
ajuste_2 <- fit(flow_2, casas_e)
graficar_evaluar(flow_2, casas_e)## `geom_smooth()` using formula 'y ~ x'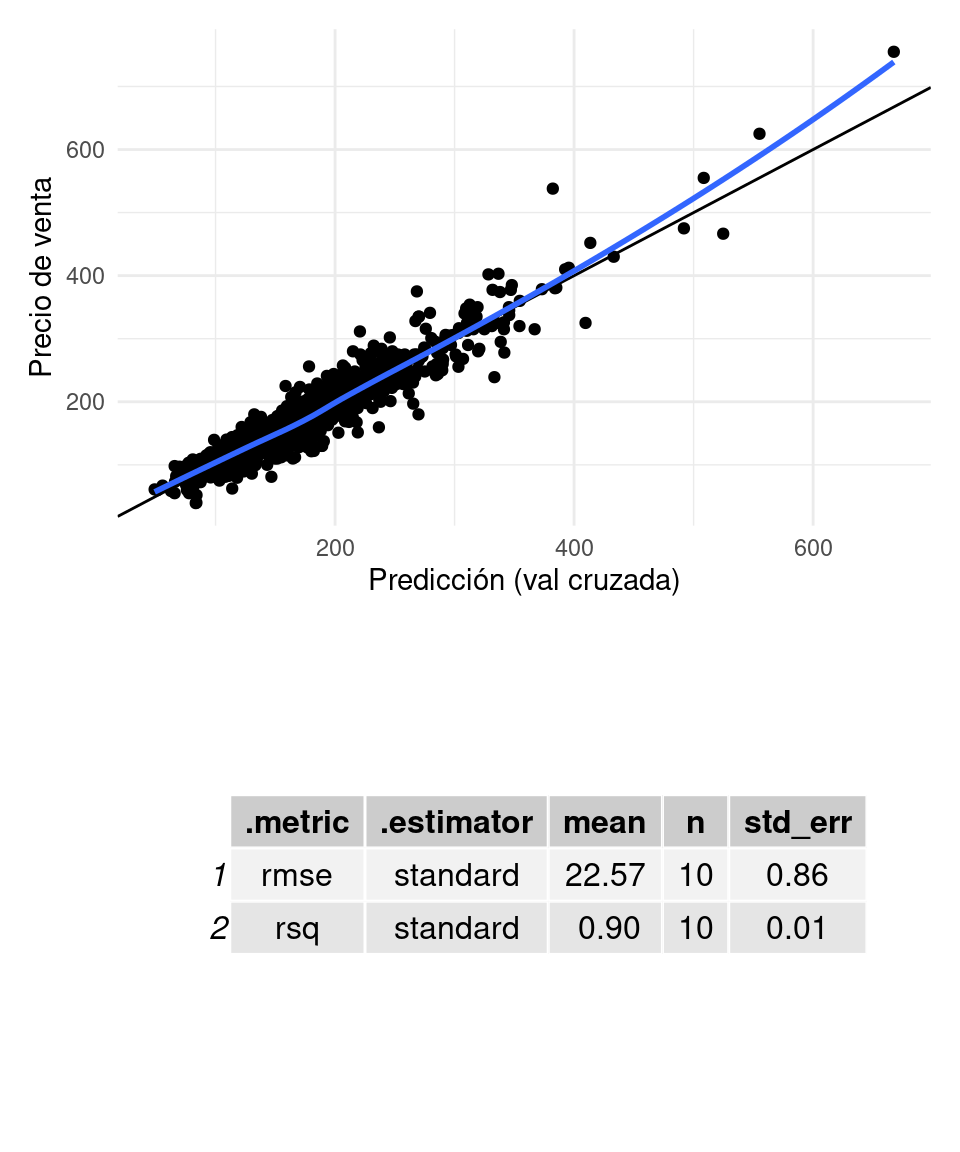
En este caso no mejoramos mucho: es posible que estas variables tengan información complementaria a la que ya habíamos incluído (por ejemplo, las zonas caras tienen casas más grandes y de más calidad, etc.).
Observación:
- El siguiente paso es utilizar regularización para afinar el desempeño. ¿Cómo puedes escoger los hiperparámetros mixture y penalty?
- Después de esto, evalúa tu modelo con la muestra de prueba que separamos.
7.6 Categorización de variables
En categorización de variable, intentamos hacer un ajuste local en distintas partes del espacio de entradas. La idea es construir cubetas, particionando el rango de una variable dada, y ajustar entonces un modelo usando la variable dummy indicadora de cada cubeta.
Cuando la relación entre entradas y salida no es lineal, podemos obtener menor sesgo en nuestros modelos usando esta técnica. Nótese sin embargo que estamos tirando información potencialmente útil dentro de cada corte, y quizá incrementando varianza pues necesitamos estimar varios parámetros.
En este ejemplo, escogimos edades de corte aproximadamente separadas por 10 años, por ejemplo:
dat_wage <- read_csv("../datos/wages.csv")
ggplot(dat_wage, aes(x=age, y=wage)) +
geom_point(alpha = 0.2) +
facet_wrap(~education)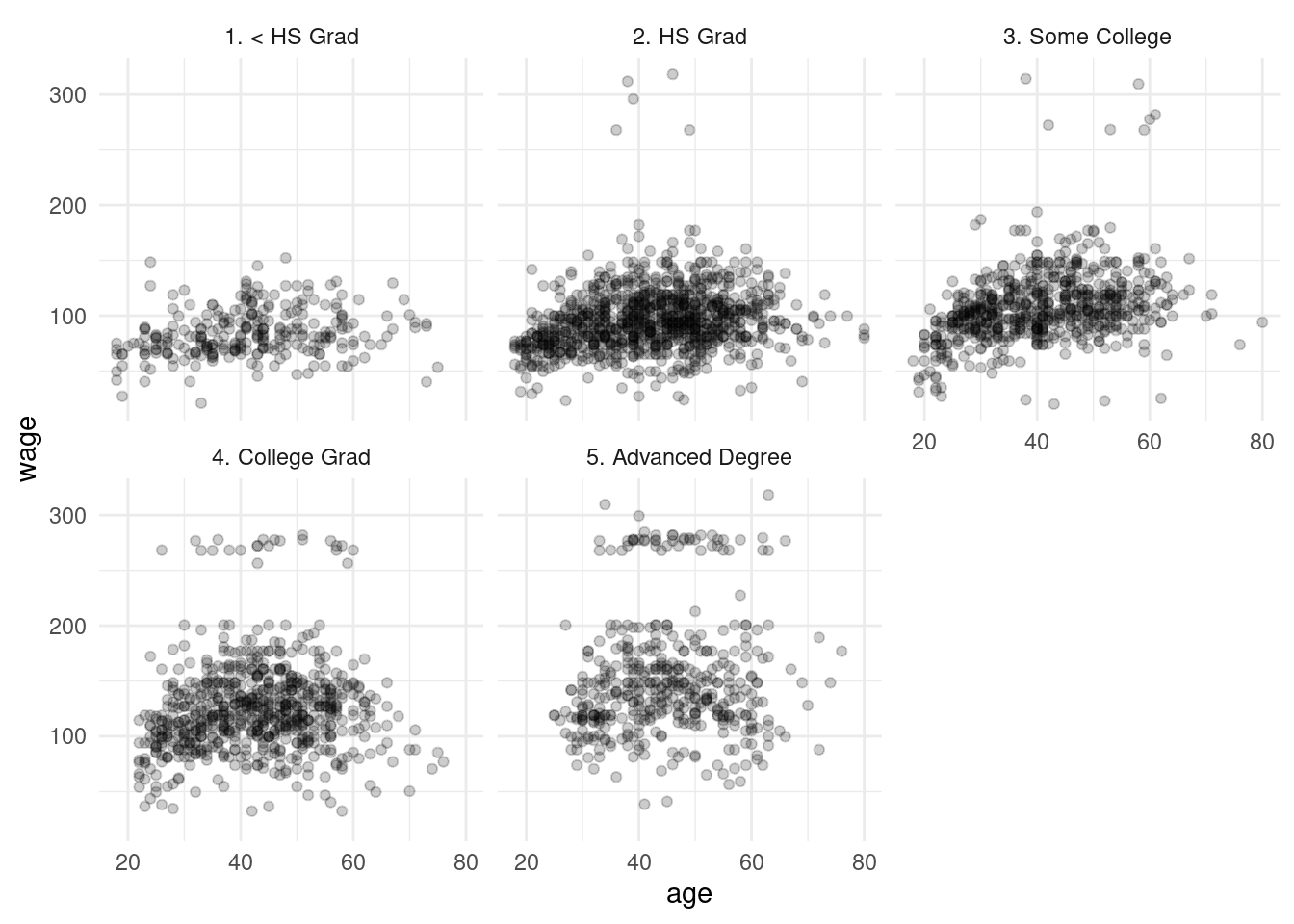
rc_salarios_prep <- recipe(wage ~ ., dat_wage %>% select(age, education, wage)) %>%
step_cut(age, breaks = seq(30, 70, 10)) %>%
step_dummy(age) %>%
step_dummy(education) %>%
step_interact(~ matches("age_"):matches("education_")) %>% prep
datos_prep <- juice(rc_salarios_prep)
ajuste <- linear_reg() %>% set_engine("lm") %>%
fit(wage ~ ., datos_prep)
ajuste_tbl <- predict(ajuste, datos_prep) %>%
bind_cols(dat_wage %>% select(wage, education, age))
ggplot(ajuste_tbl) + geom_point(aes(x=age, y=wage), alpha = 0.2) +
geom_line(aes(x=age, y=.pred), colour = 'red', size=1.1) +
facet_wrap(~education)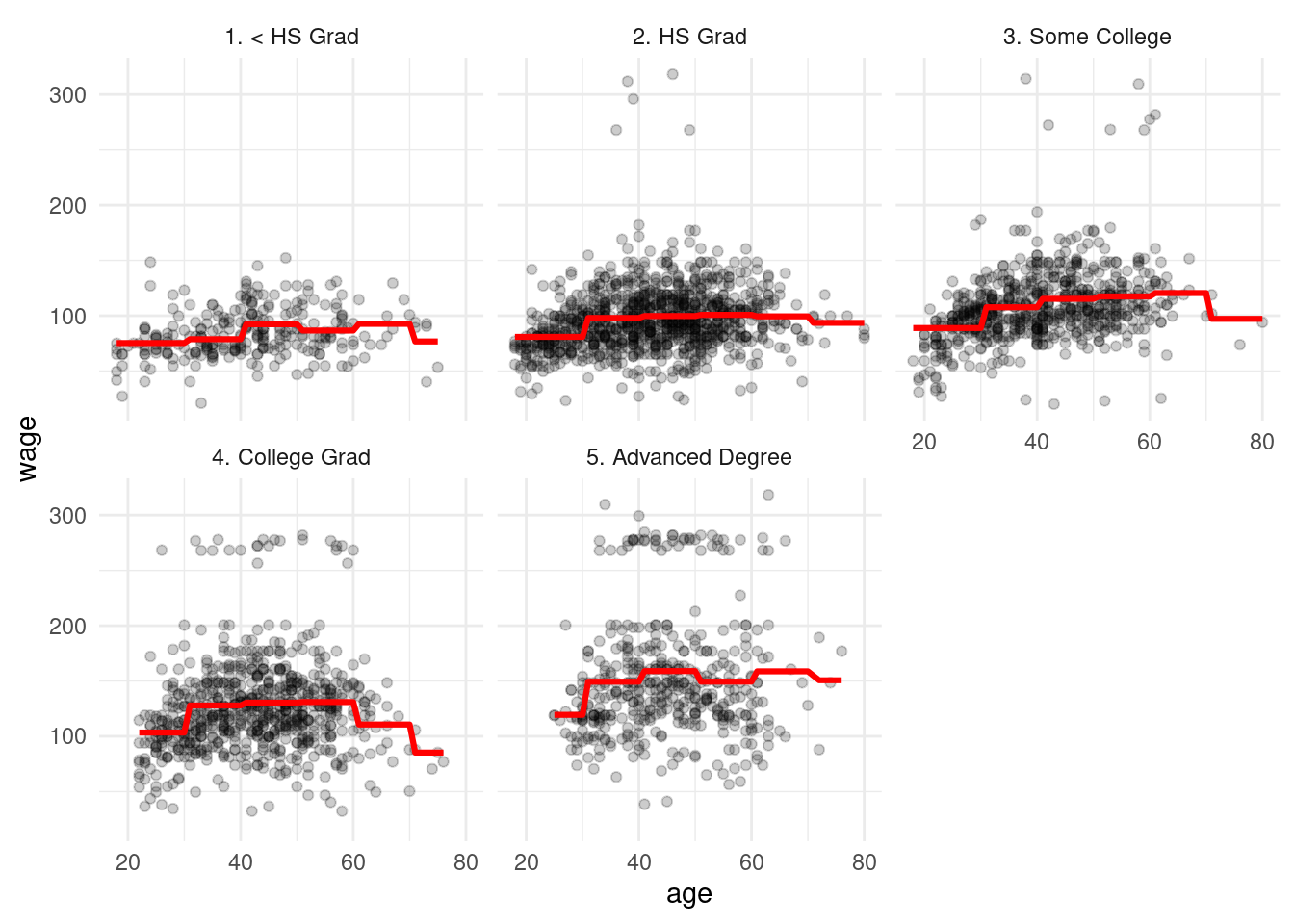
Y nótese que ajustamos un valor para cada rango de edad en cada uno de los grupos de educación (pues pusimos una interacción).
- Podemos escoger los puntos de corte en lugares que son razonables para el problema (según rangos en los es razonable modelar como una constante).
- También podemos hacer cortes automáticos usando percentiles de los datos: por ejemplo, cortar en cuatro usando los percentiles 25%, 50% y 75%. Con más datos es posible incrementar el número de cortes.
- Nótese que cuando hacemos estas categorizaciones estamos incrementando el número de parámetros a estimar del modelo (si hacemos tres cortes, por ejemplo, aumentamos en 3 el número de parámetros).
Las categorizaciones de variables pueden ser útiles cuando sabemos que hay efectos no lineales de la variable subyacente (por ejemplo, edad o nivel socioeconómico), y las categorías son suficientemente chicas para que el modelo localmente constante sea razonable.
Sin embargo, muchas veces otros tipos de transformaciones pueden dar mejoras en sesgo y en varianza en relación a categorización.:
7.7 Splines (opcional)
En estos ejemplos, también es posible incluir términos cuadráticos para modelar la relación, por ejemplo:
rc_salarios_prep <- recipe(wage ~ ., dat_wage %>% select(age, education, wage)) %>%
step_poly(age, degree = 2) %>%
step_dummy(education) %>%
step_interact(~ mathes("age"):matches("education_")) %>% prep
datos_prep <- juice(rc_salarios_prep)
ajuste <- linear_reg() %>% set_engine("lm") %>%
fit(wage ~ ., datos_prep)
ajuste_tbl <- predict(ajuste, datos_prep) %>%
bind_cols(dat_wage %>% select(wage, education, age))
ggplot(ajuste_tbl) + geom_point(aes(x=age, y=wage), alpha = 0.2) +
geom_line(aes(x=age, y=.pred), colour = 'red', size=1.1) +
facet_wrap(~education)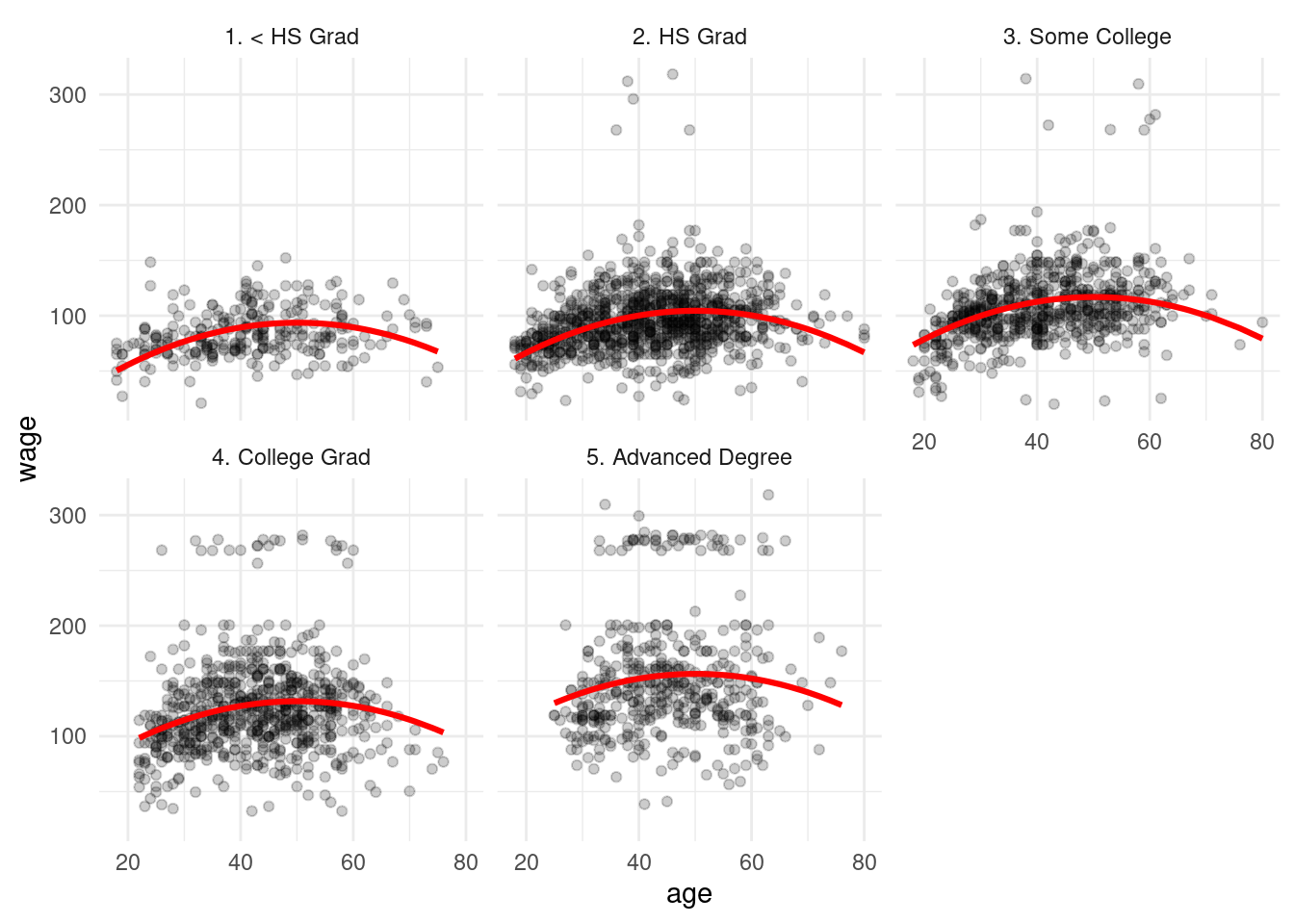
Nótese que con este método obtenemos un ajuste comparable, pero utilizando menos de la mitad de los parámetros.
Estas dos técnicas (polinomios y categorización) para hacer más flexible el modelo lineal tienen algunas deficiencias:
- Muchas veces usar potencias de variables de entrada es una mala idea, pues fácilmente podemos encontrar problemas numéricos (potencias altas pueden dar valores muy chicos o muy grandes).
- La categorización de variables numéricas puede resultar en predictores con discontinuidades, lo cual no siempre es deseable (interpretación), y requiere más parámetros para capturar estructuras que varían de manera continua.
Una alternativa es usar splines, que son familias de funciones con buenas propiedades que nos permiten hacer expansiones del espacio de entradas. No las veremos con detalle, pero aquí hay unos ejemplos:
Por ejemplo, podemos usar B-spines, que construyen “chipotes” en distintos rangos de la variable de entrada (es como hacer categorización, pero con funciones de respuesta suaves):
library(splines2)
age <- seq(18,80, 0.2)
splines_age <- bSpline(age,
#knots = c(25, 35, 45, 55, 65),
knots = c(40, 60),
degree = 3)
matplot(x = age, y = splines_age, type = 'l')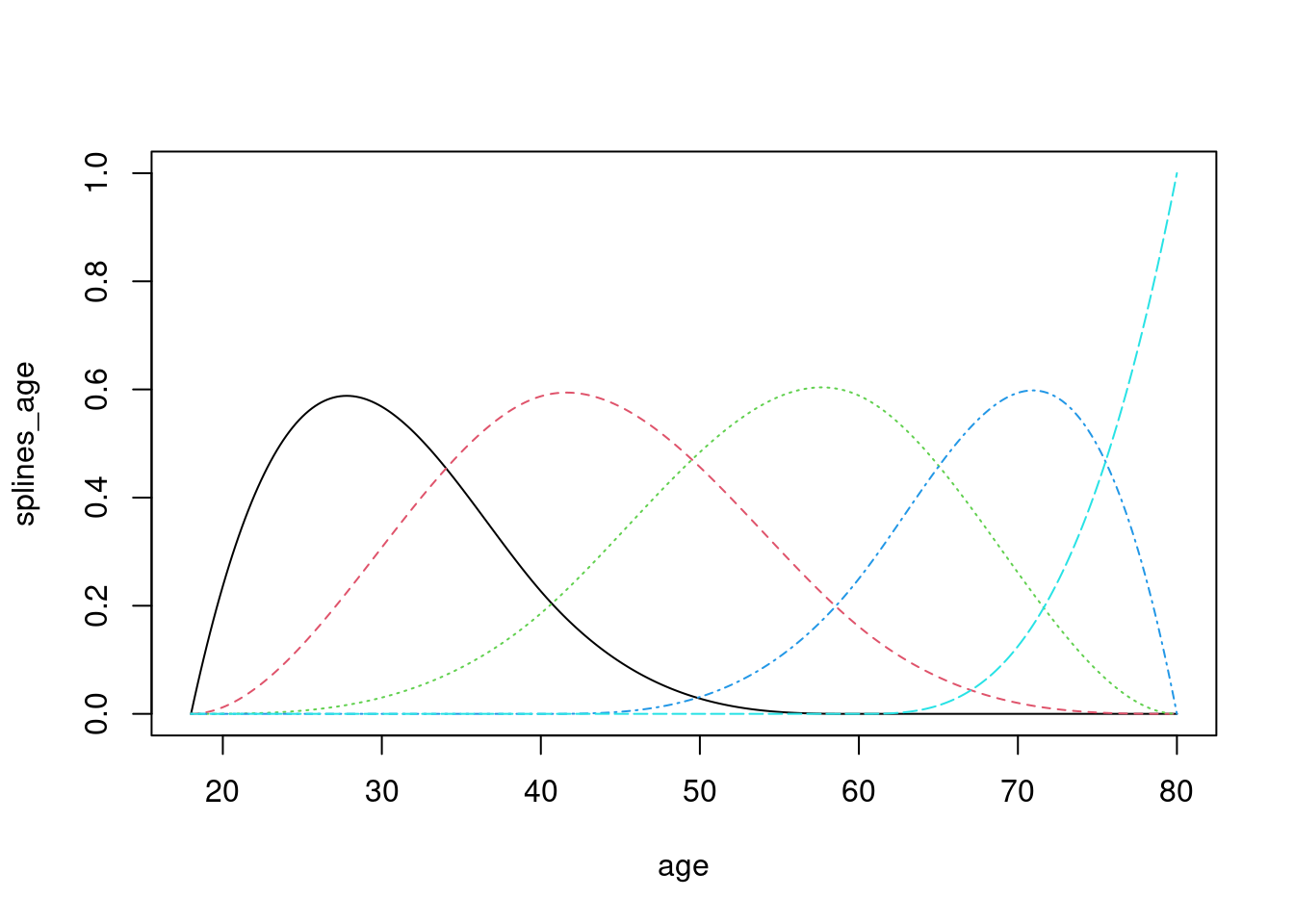
Observación: estos splines son como una versión suave de categorización de variables numéricas. En particular, los splines de grado 0 son justamente funciones que categorizan variables:
splines_age <- bSpline(age,
knots = c(25, 35, 45, 55, 65),
degree = 0)
matplot(splines_age, type='l')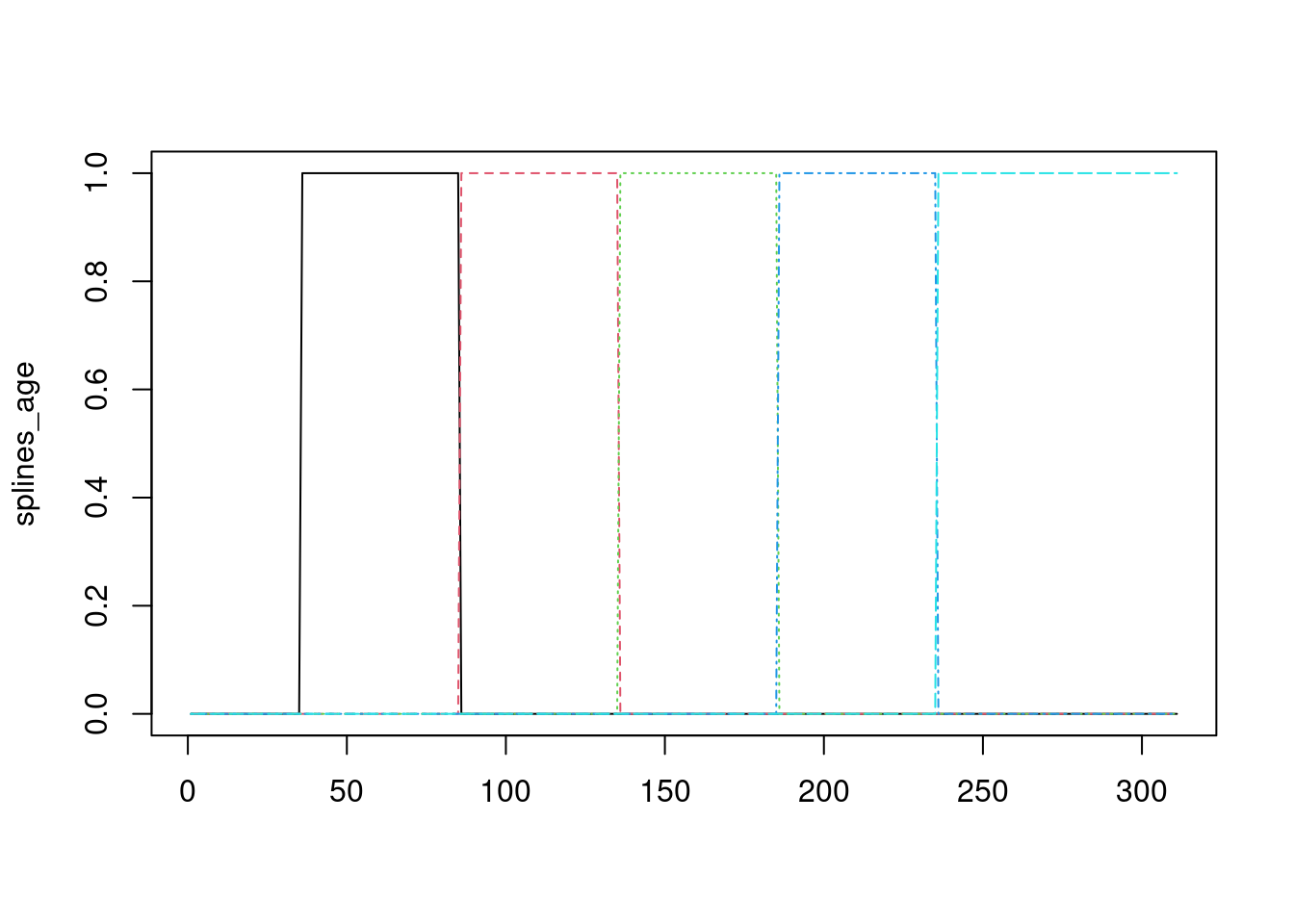
Por ejemplo: si expandimos el espacio de entradas con estos splines y corremos el modelo:
dat_wage <- read_csv("../datos/wages.csv")
# nudos en cuantiles 1/3 y 2/3, por ejemplo:
cuantiles_edad <- quantile(dat_wage$age, c(1/3, 2/3))
cuantiles_edad## 33.33333% 66.66667%
## 37 48rc_salarios_prep <- recipe(wage ~ ., dat_wage %>% select(age, education, wage)) %>%
step_bs(age, degree = 3, options = list(knots = c(30, 50, 70))) %>%
step_dummy(education) %>%
step_interact(~ mathes("age"):matches("education_")) %>% prep
datos_prep <- juice(rc_salarios_prep)
ajuste <- linear_reg() %>% set_engine("lm") %>%
fit(wage ~ ., datos_prep)
ajuste_tbl <- predict(ajuste, datos_prep) %>%
bind_cols(dat_wage %>% select(wage, education, age))
ggplot(ajuste_tbl) + geom_point(aes(x=age, y=wage), alpha = 0.2) +
geom_line(aes(x=age, y=.pred), colour = 'red', size=1.1) +
facet_wrap(~education)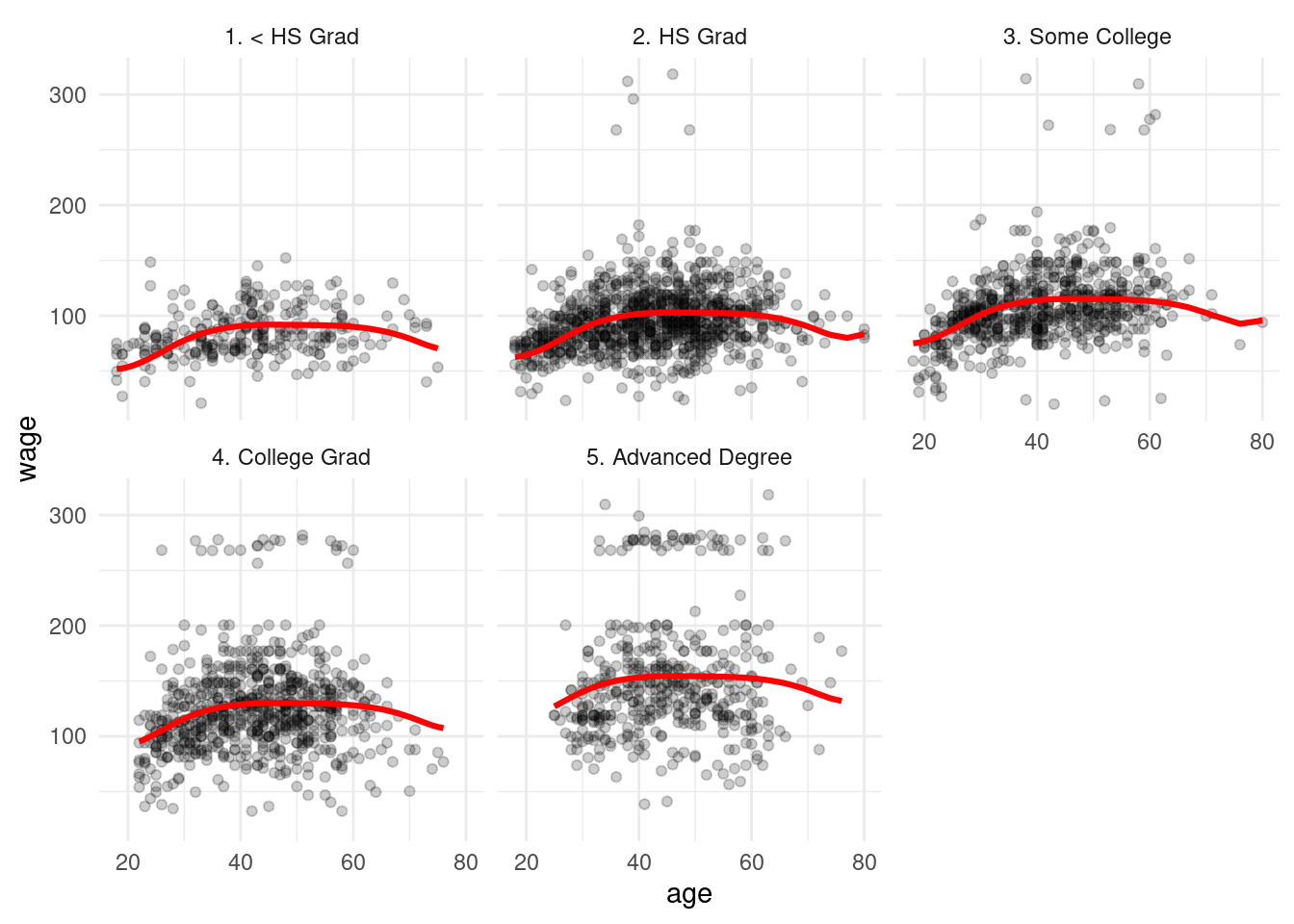
Hay otras bases, como los i-splines, que tienen usos particulares (por ejemplo cuando queremos hacer regresión monótona, podemos restringir sus coeficientes a valores negativos). Este tipo de splines son similares a los que utilizamos implícitamente en redes neuronales. Una base de i-splines es por ejemplo:
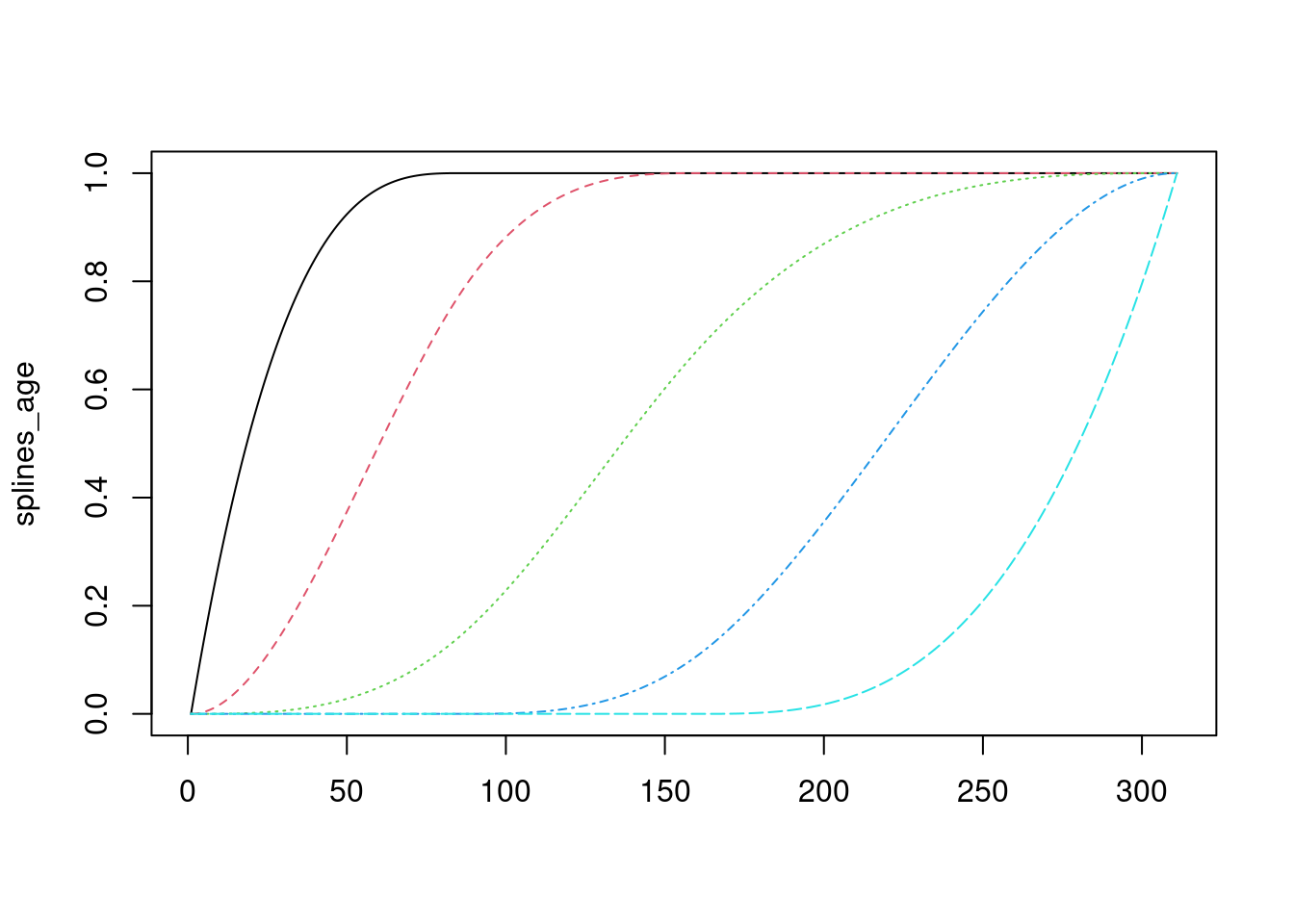
Observación: usa regularización para este ejemplo. ¿Qué parte crees que podríamos mejorar si usamos regresión ridge, por ejemplo?
7.8 Modelando en escala logarítmica
En muchos problemas, es natural transformar variables numéricas con el logaritmo. Supongamos por ejemplo que en nuestro problema la variable \(y\) es positiva, y también las entradas son positivas. En primer lugar podríamos intentar modelar \[ y = b_0 + \sum b_j x_j, \] pero también podemos transformar las entradas y la salida para construir un modelo multiplicativo: \(y' = log(y) = b_0 + \sum b_k \log(x_j)\) y ahora queremos predecir el logaritmo de \(y\), no \(y\) directamente.
Esta tipo de transformación tiene dos efectos:
- Convierte modelos aditivos (regresión lineal) en modelos multiplicativos en las variables no transformadas (pero lineales en escala logarítmica). Esta estructura tiene más sentido para algunos problemas, y es más razonable que la forma lineal aplique para este tipo de problemas.
- Comprime la parte superior de la escala en relación a la parte baja, y esto es útil para aminorar el efecto de valores atípicos grandes (que puede tener malos efectos numéricos y también pueden producir que los atipicos dominen el error o la estimación de los coeficientes).
Ejemplo
Consideramos predecir el quilataje de
set.seed(22)
diamonds_muestra <- sample_n(diamonds, 1000)
ggplot(diamonds_muestra, aes(x=carat, y=price)) + geom_point() +
geom_smooth(method="lm")## `geom_smooth()` using formula 'y ~ x'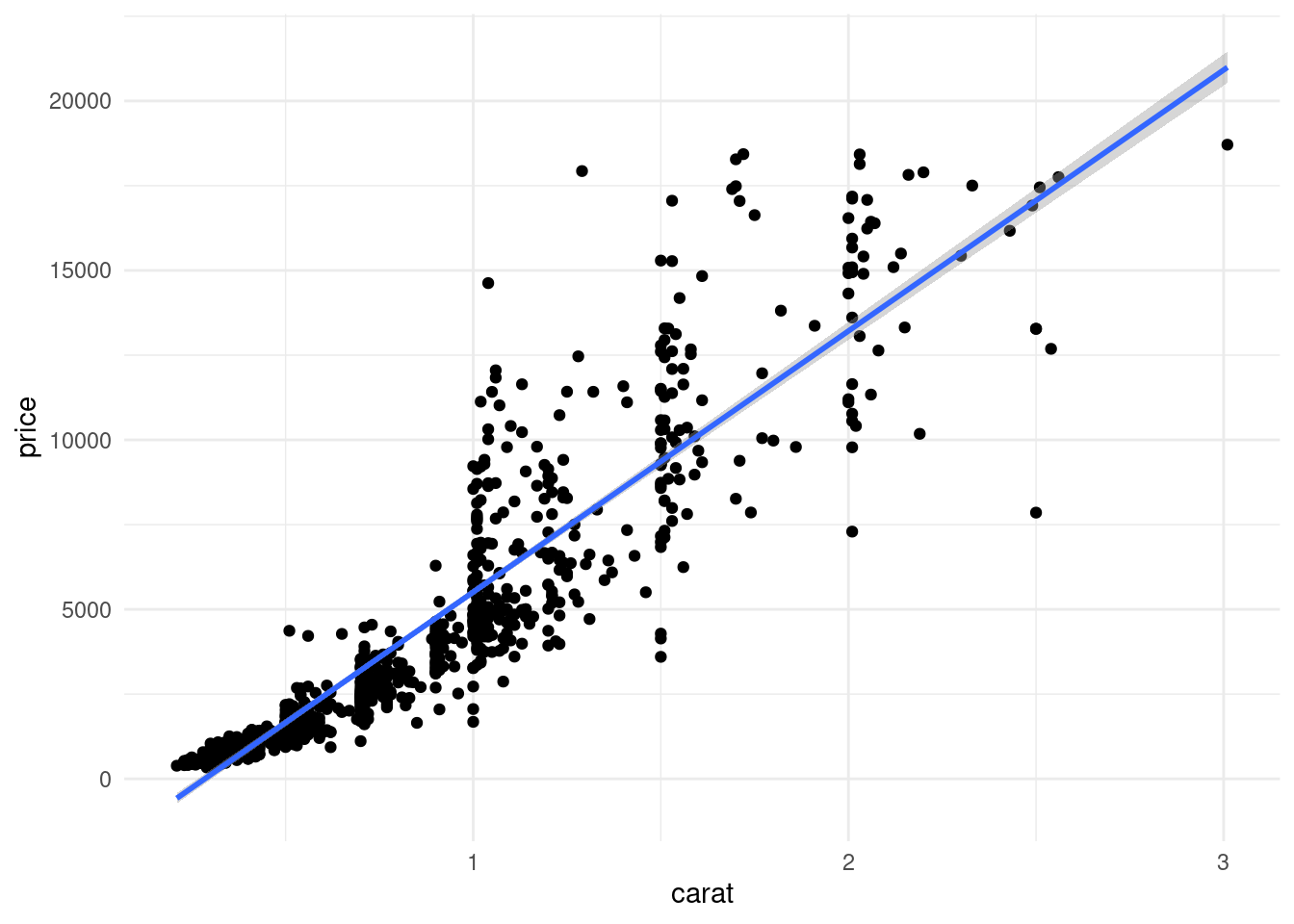
Nótese que el modelo lineal está sesgado, y produce sobrestimaciones y subestimaciones para distintos valores de \(x\). Aunque podríamos utilizar un método más flexible para este modelo, una opción es transformar entrada y salida con logaritmo:
diamonds_muestra <- diamonds_muestra %>%
mutate(log_price = log(price), log_carat = log(carat))
ggplot(diamonds_muestra, aes(x=log_carat, y=log_price)) + geom_point() +
geom_smooth(method = "lm")## `geom_smooth()` using formula 'y ~ x'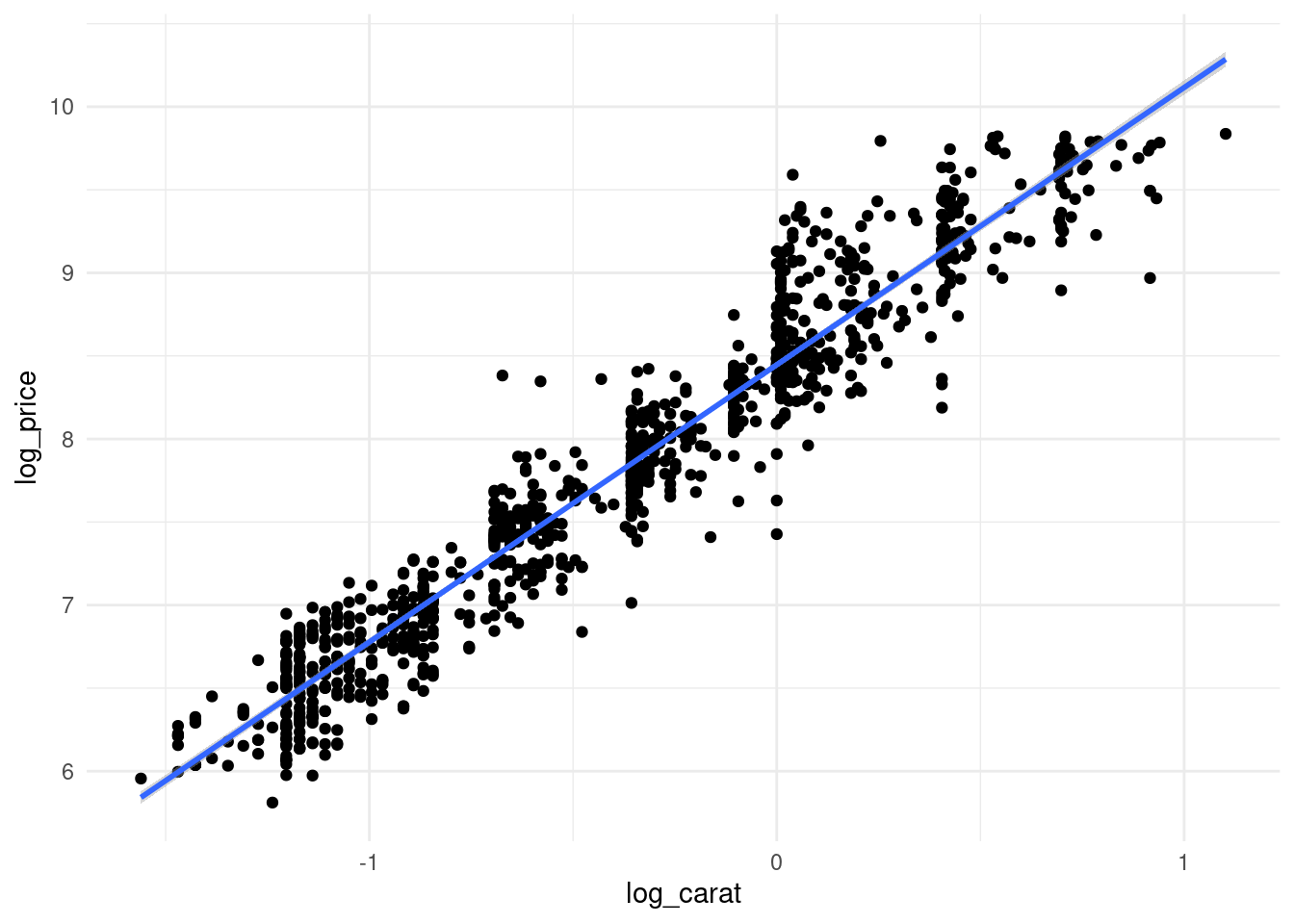
Podemos graficar también en unidades originales:
ggplot(diamonds_muestra, aes(x=carat, y=price/1000)) + geom_point() +
geom_smooth(method = 'lm') +
scale_x_log10(breaks=2^seq(-1,5,1)) + scale_y_log10(breaks=2^seq(-2,5,1))## `geom_smooth()` using formula 'y ~ x'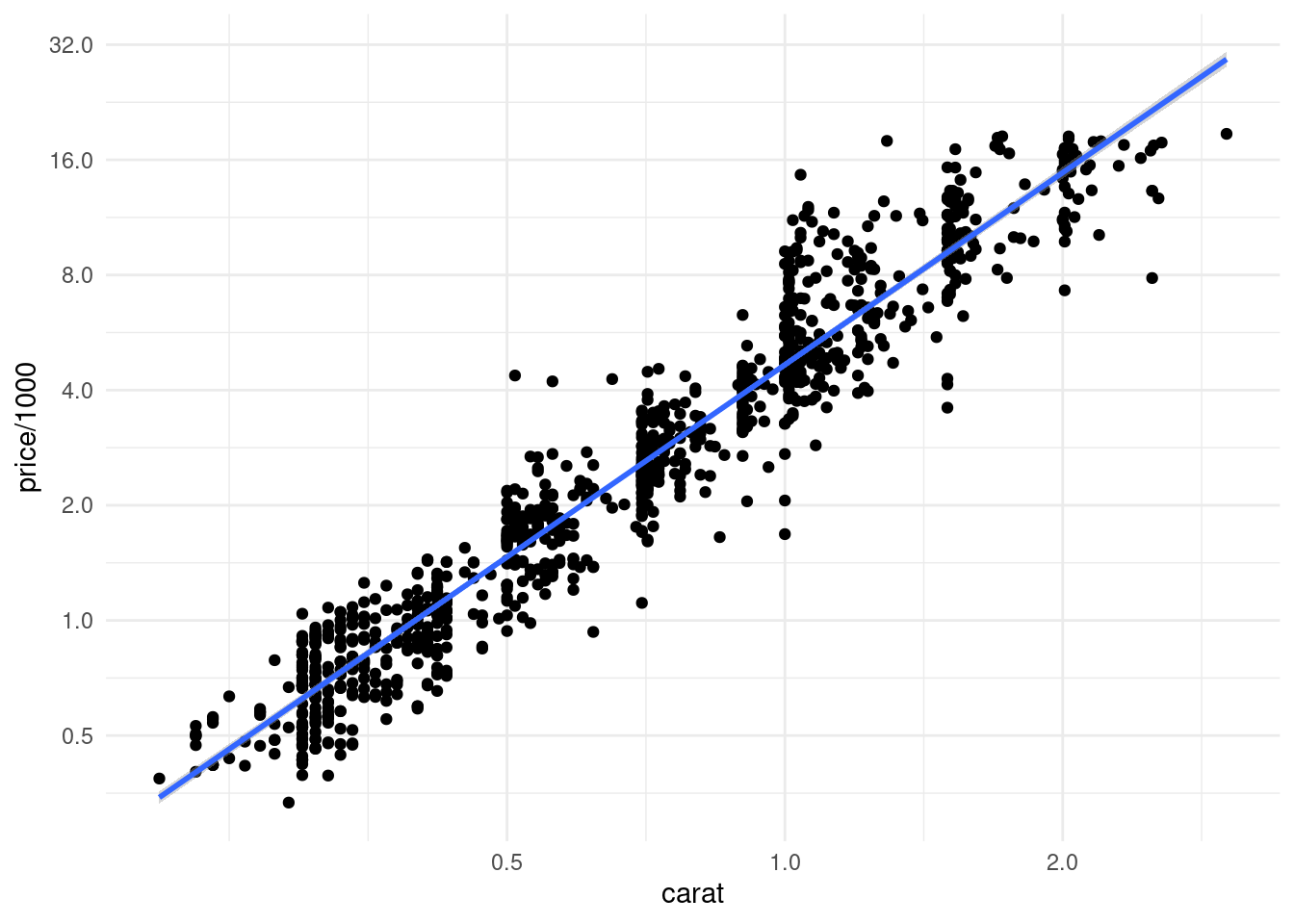
Y vemos que la relación entre los logaritmos es lineal: redujimos el sesgo sin los costos adicionales de varianza que implica agregar más variables e interacciones. En este caso, esta relación es naturalmente multiplicativa (un 10% de incremento relativo en el peso produce un incremento constante en el precio).
- Cuando una variable toma valores positivos y recorre varios órdenes de magnitud, puede ayudar transformar con logaritmo o raíz cuadrada (esto incluye transformar la variable respuesta).
- Muchas veces es natural modelar en la escala logarítmica, como en el ejemplo de los diamantes.
- También tiene utilidad cuando las variables de respuesta o entrada tienen distribuciones muy sesgadas a la derecha (con algunos valores órdenes de magnitud más grandes que la mayoría del grueso de los datos). Tomar logaritmos resulta en mejoras numéricas, y evita que algunos valores atipicos dominen el cálculo del error.
- Menos común: variables que son proporciones \(p\) pueden transformarse mediante la transformación inversa de la logística (\(x = \log(\frac{p}{1-p})\).)
Discusión:
En un modelo lineal usual, tenemos que si cambiamos \(x_j \to x_j + \Delta x\), entonces la predicción \(y\) tiene un cambio de \[\Delta y = b_j \Delta x.\]
Es decir, mismos cambios absolutos en alguna variable de entrada produce mismos cambios absolutos en las predicciones, independientemente del nivel de las entradas.
Sin embargo, el modelo logarítmico es multiplicativo, pues tomando exponencial de ambos lados, obtenemos:
\[y = B_0\prod x_j^{b_j}\] Entonces, si cambiamos \(x_j \to x_j + \Delta x\), el cambio porcentual en \(y\) es \[ \frac{y+\Delta y}{y} = \left ( \frac{x_j +\Delta x}{x_j}\right )^{b_j}\]
De modo que mismos cambios porcentuales en \(x\) resultan en los mismos cambios porcentuales de \(y\), independientemente del nivel de las entradas.
Adicionalmente, es útil notar que si \(\frac{\Delta x}{x_j}\) es chica, entonces aproximadamente \[ \frac{\Delta y}{y} \approx b_j \frac{\Delta x}{x_j}\] Es decir, el cambio relativo en \(y\) es proporcional al cambio relativo en \(x_j\) para cambios relativamente chicos en \(x_j\), y el coeficiente es la constante de proporcionalidad.
7.8.1 ¿Cuándo usar estas técnicas?
Estas técnicas pueden mejorar considerablemente nuestros modelos lineales, pero a veces puede ser difícil de descubrir exactamente que transformaciones pueden ser útiles. Requiere conocimiento de dominio del problema que enfrentamos. En general,
- Es mejor usar regularización al hacer este tipo de trabajo, para protegernos de varianza alta cuando incluimos varias entradas derivadas.
- Es buena idea probar incluir interacciones entre variables que tienen efectos grandes en la predicción, o interacciones que creemos son importantes en nuestro problema (por ejemplo, temperatura y viento en nuestro ejemplo de arriba, o existencia de estacionamiento y tráfico vehicular como en nuestro ejemplo de predicción de ventas de una tienda).
- Gráficas como la de arriba (entrada vs respuesta) pueden ayudarnos a decidir si conviene categorizar alguna variable o añadir un efecto no lineal.
Este es un trabajo que no es tan fácil, pero para problema con relativamente pocas variables es factible. En situaciones con muchas variables de entrada y muchos datos, pueden existir mejores opciones.
Feature Engineering and Selection: A Practical Approach for Predictive Models es un buen libro donde puedes aprender más de feature engineering. En particular, no hablamos aquí de:
- Tratamiento de datos faltantes
- Tratamiento de datos en jerarquías (por ejemplo, predicciones para hogar con datos de las personas que los componen, y otros temas de series de tiempo).